Purchase History Search: Indexing with Elasticsearch
Categories
At Empathy.co, we have been making heavy use of search engines such as Solr and Elasticsearch for years. They are key types of software in the products we build for our platform and our clients. They enable fast and effective storage and retrieval of our clients' catalogue products, simply and with little overhead.
A couple of years ago, one of our clients requested that we speed up the retrieval of their historical purchase data. They had been storing the data without considering its retrieval much. Since we had already been using Elasticsearch for this client, we promptly designed a system for ingesting and finding purchase history data, thus Purchase History Search as a separate project was born.

The challenge of Purchase History Search was ingesting a huge volume of purchase data in real time and making the data easily searchable. The introduction of the time dimension to the data is a key difference from catalogue search. Moreover, the history of purchases is private data, so creating a privacy-first system was essential.
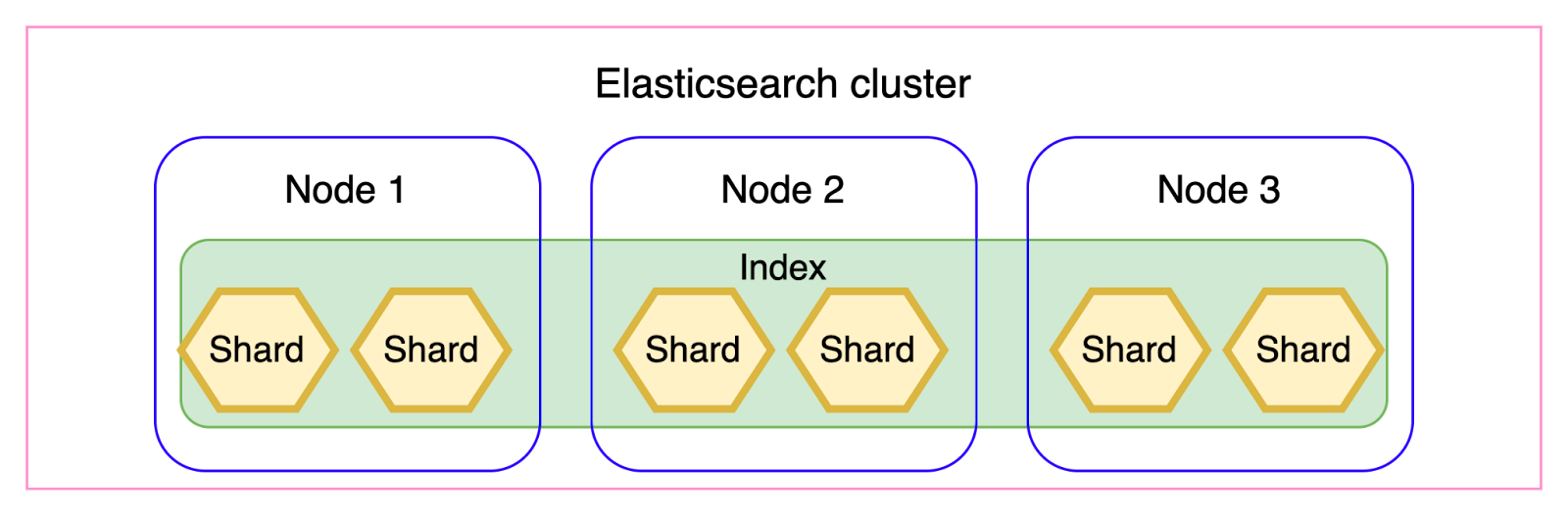
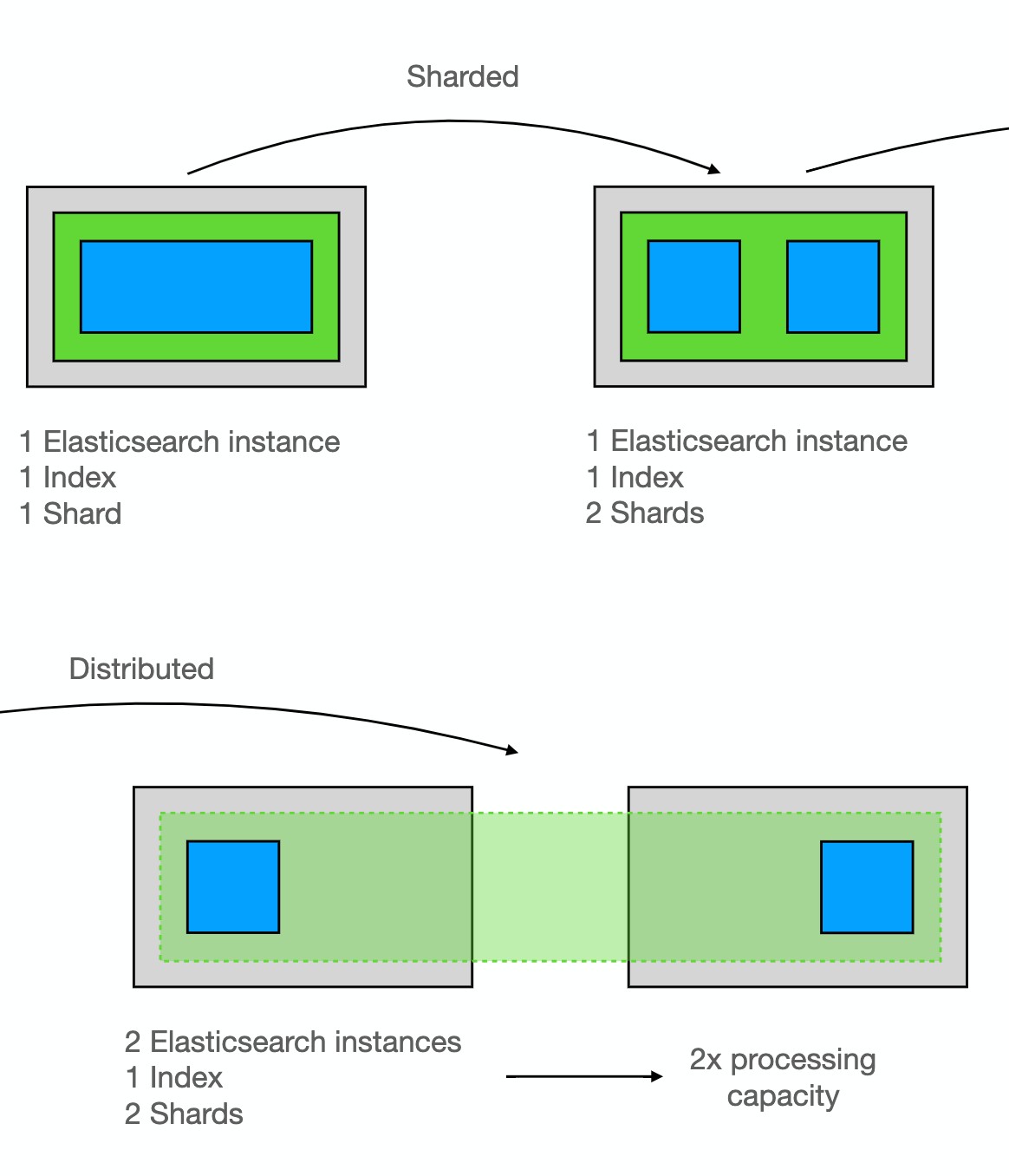
Elasticsearch works with indices that could be roughly compared to standard database tables. Each index is further divided into shards, which are essentially inverted indices that enable the efficient search of data using the terms contained within it. These shards can live in different nodes (machines) so that the index operations can be distributed and parallelized. A typical Purchase History cluster consists of three or five master nodes that manage the entire cluster, its metadata, and operations, and about six data nodes where the index shards actually reside.
At Empathy.co, for our retail clients, we usually build a new index every time there is a new catalogue using a batch or on-demand process. For Purchase History, we have a continuous stream of purchase documents going into a feed, so the mechanism changes. In this case, we use a different service called the Streaming Indexer.
Ingesting the Data
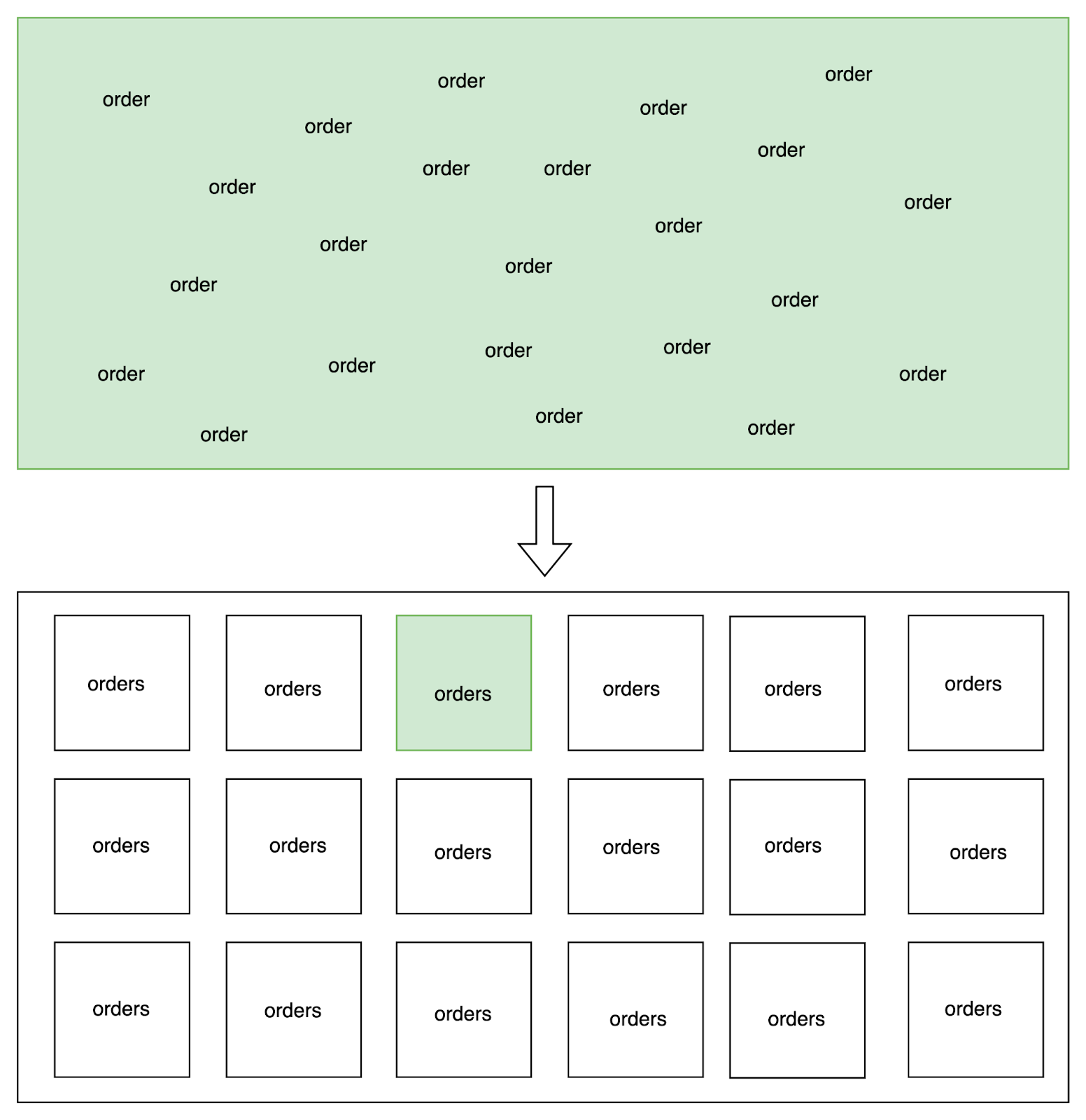
The Streaming Indexer is a scalable and stateless application that sits between the client's data feed and our Elasticsearch cluster. It fetches documents in real time and indexes them to a specific index. As the data is presented in a time-series style, it is only natural to have indices consist of a subset of the purchases. In our case, we decided to go with a monthly index. To further optimise the data storage and retrieval, it is standard for each document to have some kind of customer ID field. This ID can be employed to always route the document to the same index shard. When a shopper goes through their history, a single shard needs to be hit. It is like directing your search to a single drawer in your wardrobe.
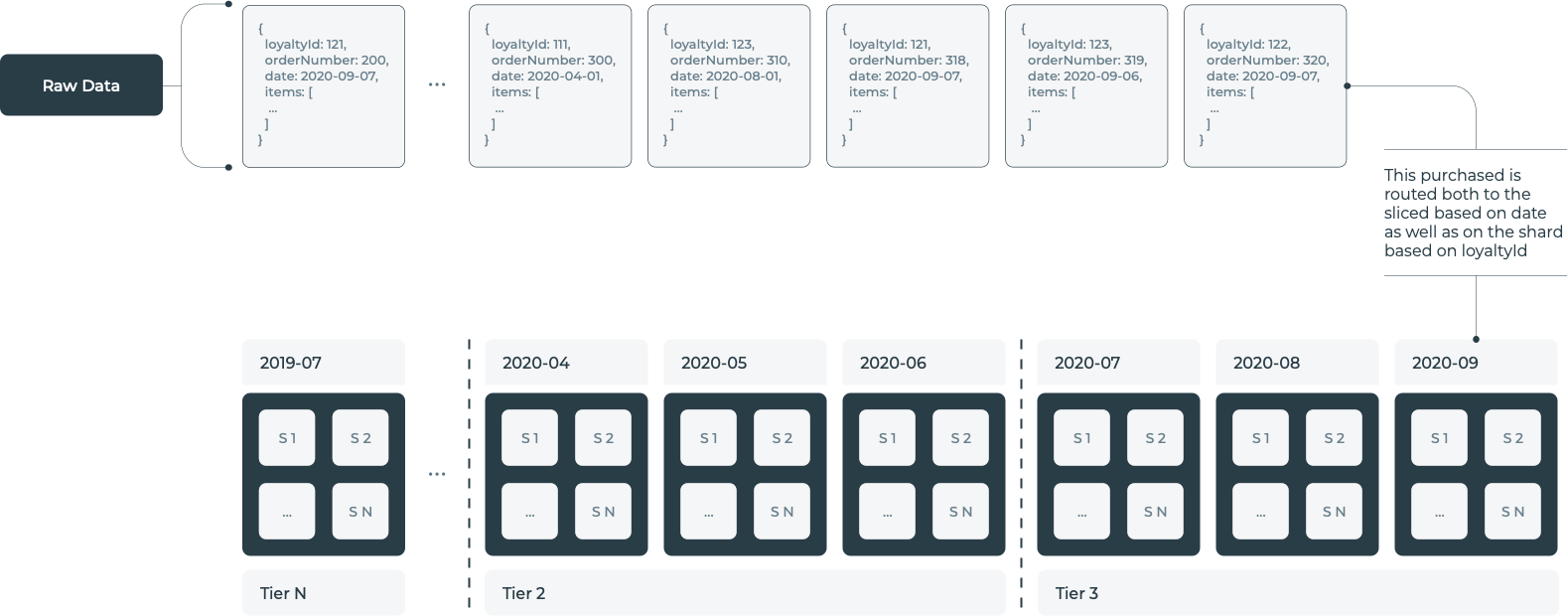
This idea of sharding is not only a performance gain, but a good first step towards a privacy-aware and decentralized Purchase History system. Even though Elasticsearch is the centralising element of the whole setup, the idea of separating data based on customers is an element that we would like to explore further. We have been researching solutions like SOLID, whose pods can resemble our idea of shards. Basically, each shard/pod would be a private, fully decentralized repository of a consumer’s data. The consumer would be in total control of it and would be able to manage who has access to what part of their data.
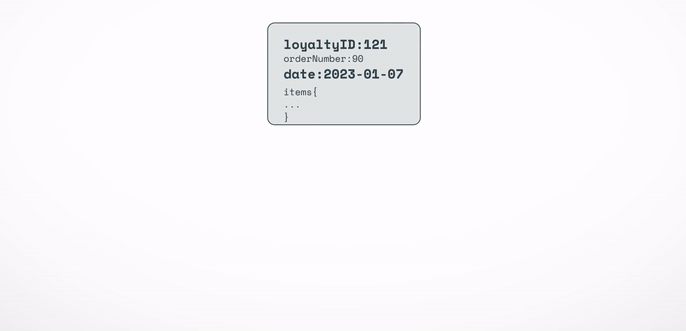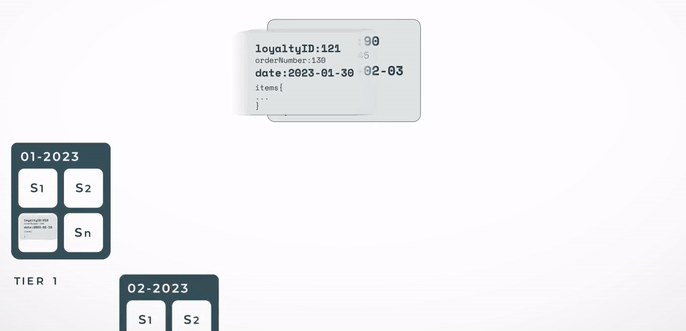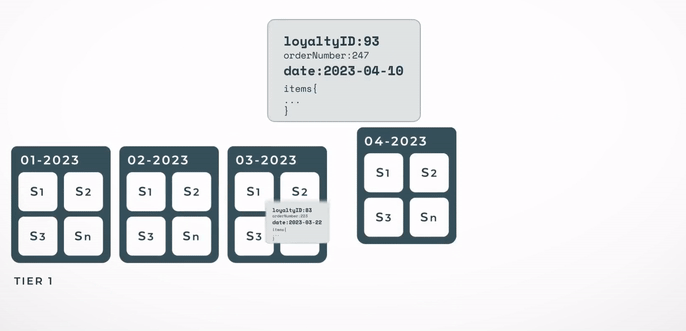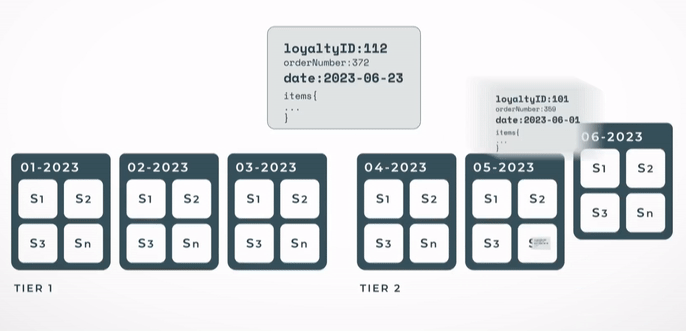
As stated, shards are grouped into indices. The picture below shows the different components regarding Elasticsearch. This index distribution of data enables the Elasticsearch cluster to scale indefinitely with no degradation of the service. Multiple instances of Elasticsearch nodes can be run so that the processing of the querying and the indexing is further distributed. Each instance can work in parallel and also each index can be queried in separately. Furthermore, settings can be tweaked for older indices, such as freezing them and making them read-only. A large proportion of our clients' searches are for the purpose of retrieving recent purchases, which usually means only one or two of the most recent indices are hit.
Accessing the Data
The second part of our Purchase History setup is the Search API itself. It is able to search effectively for purchases with a combination of filter and sorting parameters. Depending on the use cases different search parameters can be used. A typical use case is for shoppers to review their purchase history looking for details or items to repurchase. Another use case is that of our client’s customer support services, which shoppers contact in the event of mismatches between ordered and received products. This setup can also be integrated with other applications, such as a Nutrition ranking system or a Pickup virtual assistant, quickly checking clients’ purchase history to retrieve purchases to be picked up.
The Search API service is also scalable and stateless, but it is more similar to our traditional search service. To make it performant, some tricks are possible, such as using the routing data discussed earlier. Secure access and permissions are simple to set up using OAuth, for example.
As with the rest of our services, Kubernetes is used to orchestrate the deployment of all the Purchase History services. This makes them reliable and enables them to run in any cloud environment as there are no cloud-specific technologies used. Kubernetes simplifies horizontal scaling, depending on the load. For example, if traffic suddenly increases, more Search API pods can be quickly deployed to meet established latency SLAs.
Some other considerations are the retention period of the data. Our customers, or even legislation, may dictate that the data be kept for no longer than a specific period. Having the monthly indices scheme in place allows us to simply remove a full index when all the documents belonging to that month are older than the defined period.
The Future of Purchase History
The following challenge will be to configure Purchase History access in a decentralized and private scenario. This will be done hand-in-hand with merchants, as they will no longer own and have total control over their customer base’s Purchase History, but rather an interface to enable access to each customer’s shards/pods.