Frequent Pattern Mining
Categories

TL; DR
The field of Frequent Pattern Mining (FPM) encompasses a series of techniques for finding patterns within a dataset.
This article will cover some of those techniques and how they can be used to extract behavioral patterns from anonymous interactions, in the context of an ecommerce site.
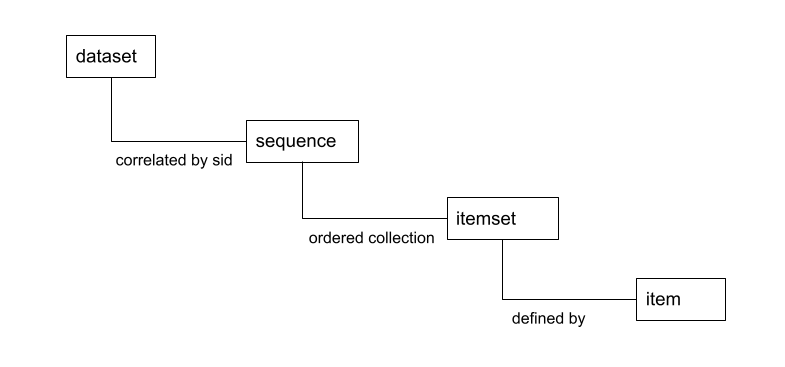
Terms and Concepts
Say that we are observing and noting down in a ledger every time a keystroke is played on a piano. For clarity, let's concede that our piano is oversimplified and only has seven notes, from A to G.
Our ledger would read something like this: A, D, F, A, C, G, A, C, B
The contents of our ledger are a data series, and each individual note is an element (a.k.a. itemset) of the series.
We know that the ordering of the notes is rather important in a melody. Thus, we can safely assume that our series is indeed a sequence (ordered data series). This is not always the case and it really depends on what information you want to learn from the data. For instance, we might be studying how frequently two particular notes are dominant in a database of melodies. Then, we wouldn't need to guarantee a sequence.
Now imagine that we want to detect riffs. A riff is a short sequence of notes that occur several times in the structure of a melody. In our nomenclature, a riff is then a subsequence. A subsequence of length 'n' is also called an n-sequence.
For example, take this popular tune. Can you hum along?

So this is the goal of FPM put simply: find the subsequences with their frequency, i.e. how many times they are observed.
In order to make things more interesting, let's consider many pianos playing at the same time. We can simultaneously write all the notes played, but we need an additional annotation to be able to tell them apart, e.g., P1 for the first piano, P2 for the second one, and so forth. This is the sid (sequence identifier).
Until now, we have considered every element to be defined by a single piece of data (e.g., 'A'), but that's obviously insufficient. Musical notes have more aspects to them than the tone: duration is also a key piece of data. We can improve our modeling by defining two aspects for our itemsets: tone and duration. For example, {tone: B, duration: 4} is an itemset defined by two items. Note that there is no concept of ordering for the items belonging to an itemset. They all occur at the same time.
This twist allows for more interesting exercises. We could, for instance, focus our attention on finding a dominant rhythm in the melodies. Or, we could look for recurring patterns of notes combining a particular sequence of tones, followed by any tone with a particular duration.
Modeling Behavior
We will now apply the concepts above for modeling the behavioral trends observed in an ecommerce website.
We take the clickstream as our dataset, i.e., the atomic interactions that shoppers are producing on the website. These interactions include things like performing a search, clicking on a product, etc.
The Session ID is a perfect match to use as the sid, since this concept is widely used across the web for correlation purposes. Note that no other profiling data is needed. Plus, Session ID has desirable properties to it regarding privacy and security:
- Meaningless
- Volatile (only used during a session's lifespan)
- Unique
- Context-specific (not shared between sites)
The shoppers' interactions are then grouped by Session ID and sorted by timestamp when we observe them. The resulting sessions are our sequences, thus the interactions are itemsets.
Next, we must define the interactions through their items. The first consideration is that we have different kinds of shopper interactions. Thus it's logical to consider this an important item. Let's name it eventType. This may vary between websites, depending on the user experience. Let's initially consider three main types:
- eventType: query (the shopper performs a query).
- eventType: click (the shopper clicks on a product card from the results).
- eventType: add2cart (the shopper adds a product to the shopping cart).
Query
At the very least, a query action is defined by its query terms. We also apply normalization processing to the query terms to improve the homogeneity of input data, e.g., lowercasing and transforming plural to singular words.

Click / Add2Cart
Click and add2cart are very similar regarding their relevant items, although the latter is usually a stronger signal so it's a good idea to keep them apart. The product ID is their most descriptive item, and the position of this product in the result list may also be relevant as it generally introduces bias in shoppers' behavior.
We also enrich the itemset with attributes from the shop's catalogue, in order to improve the aggregation factor. Consider that it's easier to discover patterns from items with a greater aggregation factor.

The selection of attributes to include in the itemsets has a big impact in the outcome of the FPM. The choices will depend primarily on the goal of the application. What kind of patterns are you aiming to discover?
Aggregation Factor
When a particular item occurs a lot across itemsets, then we say that it has a big aggregation factor. E.g., you can expect to see a lot of occurrences of the item 'eventType:query'.
The aggregation factor is necessary for discovering patterns, but it can also spoil your FPM with obvious facts. For instance, you could end up with the following top patterns:
- {eventType:query}, {eventType:query}
- {eventType:query}, {eventType:query}, {eventType:click}
- {eventType:query}, {eventType:click}
The patterns based on items like 'eventType:query' are eclipsing other patterns that are probably more interesting to learn about.
A possible optimization in this case is crossing some features together in order to break the strong aggregation factor, thus gaining increased granularity, e.g.:
- {eventType:query, terms:'cargo jumpsuit'} --> {query:'cargo jumpsuit'}
- {eventType:click, productId:'12345'} --> {click:'12345'}
Therefore leading to more intriguing patterns like:
- {query:'cargo jumpsuit'}, {click:'12345'}
In Action
Let's take a look at how to run FPM using Apache Spark's PrefixSpan implementation.
First, we'd typically prepare the data from clickstream as an Apache DataFrame. The key column here is sequence. Note that we have nested arrays (sequences of itemsets) in that column.
+-------+---------------------------------------------------------------+
|session|sequence |
+-------+---------------------------------------------------------------+
|131ABC |[[query:jacket], [click:p3, size:M, dept:casual], [click:p2, size:L, dept:casual]] |
|130ABC |[[query:jacket], [click:p2, size:L, dept:casual], [query:sport], [click:p3, size:M, dept:casual], [add2cart:p3, size:M, dept:casual]] |
|125ABC |[[click:p1, size:40, dept:footwear], [add2cart:p3, size:M, dept:casual], [click:p2, size:M, dept:casual]] |
|123ABC |[[query:sport], [click:p1, size:38, dept:footwear], [click:p3, size:M, dept:casual]] |
|124ABC |[[query:sweater], [click:p2, size:L, dept:casual], [prd:p3, size:M, dept:casual], [add2cart:p3, size:L, dept:casual], [query:shirt], [click:p2, size:L, dept:casual]] |
+-------+---------------------------------------------------------------+
Running FPM on top of this prepared DataFrame is simple:
def run(df: DataFrame): DataFrame = {
new PrefixSpan()
.setMinSupport(minSupport)
.setMaxPatternLength(maxPatternLength)
.setMaxLocalProjDBSize(maxLocalProjDBSize)
.findFrequentSequentialPatterns(df)
}
- minSupport: A lower threshold for discarding patterns that are not representative enough in the observed sessions. For a given pattern, support is calculated as
num_sessions_present/total_sessions. This value is therefore a relative amount (0-1). - maxPatternLength: An upper threshold for pattern length. E.g., if this value is set to 5, then the length of the output patterns would be between 1 and 5.
- maxLocalProjDBSize: This is an internal value that determines how many resources, in terms of memory, can be dedicated to building the internal representation (DB sequences) when running the algorithm.
It's worth mentioning that fine-tuning minSupport and maxPatternLength critically impacts performance.
As output, we get another DataFrame with the results of the analysis.
+------------------------------------------------------------------+----+
|sequence |freq|
+------------------------------------------------------------------+----+
|[[size:M, dept:casual], [click:p3]] |53 |
|[[query:jacket], [click:p3, dept:casual, size:L]] |34 |
|[[query:shirt], [size:M, dept:casual], [add2cart:p2]] |31 |
+------------------------------------------------------------------+----+
Note that many of the resulting itemsets are now "incomplete". They are now like templates. It tells you the common factors extracted from the original itemsets observed.
Alternative
Apache Spark also provides another implementation for performing FPM: FP-Growth.
It's interesting to know the differences, as it can also be a valid approach for some of the use cases.
- Unordered discovery: When extracting patterns, FP-Growth doesn't take the order of the sequences into consideration. This can be handy for detecting elements that are frequently found together, not necessarily with the implicit cause-effect relationship that ordering implies. For instance, "products bought together" is a case of unordered discovery.
- Simplified data model: The elements from input sequences are not expected as itemsets. They are not nested arrays, but plain values. This means that you can't expect to extract a common factor from composed elements. This may, however, still be valid for your use case.
- Repeated elements not allowed: The same element can't appear twice in a given sequence. You'll need to filter out those cases before running the algorithm.
What Next?
Now that you have discovered the representative patterns in your data, you can interpret this info statistically as a source of predictions and recommendations for your shoppers. Optimizing the most frequent shopper journeys on a website (e.g., by suggesting shortcuts) is another interesting use case.
Patterns can be used to learn trends or association rules, so stay tuned for a post on that topic!
References
 Contributors to Wikimedia projects
Contributors to Wikimedia projects