Image Generation with AI Models
Categories

Introduction
In recent years, improvements in results from AI models have come from two different sources.
On one hand, the improvement in hardware capabilities in terms of raw computational power has enabled larger models to be trained. As a result, AI models have been able to get bigger and bigger (i.e. have more and more parameters). The increasing of parameters has also made these models more precise, but there is another component besides having hardware and bigger models — we need a way to train them. To do so, enormous datasets are required; as parameters increase, dataset size also has to increase accordingly. For example, DALL·E 2, one of the biggest models in the text-to-image model space with about 3.5 billion parameters, was trained on a 650 million image-caption pair dataset obtained from multiple sources all over the internet. (Dataset creation is a whole other issue, so we will not delve further into that topic.)
On the other hand, there have been architectural improvements of the results obtained by these huge text-to-image models, which can’t be achieved by brute force alone. In recent years, with the breakthrough of the so-called diffusion models, there has been an enormous improvement in the results produced by new AI models even without increasing the parameters of said models (e.g. DALL·E 2 has fewer parameters compared to its previous version, but performs much better).
Even though research and development of new models is continual, 2022 has seen explosive growth in the Image Generation field. Where before there were small improvements on a year-to-year basis, this year has brought great improvements on a monthly, weekly, and even daily basis. In fact, while writing this article, Version 2 of Stable Diffusion was just released on November 24. While this article will not cover the latest version of Stable Diffusion, all ways of working related to this model that will be covered can most likely be applied to the latest version.
Getting Started with Image Generation Models
The first step to begin using Image Generation for personal use is to decide which model to use. As of now, there are three main models for image generation: Stable Diffusion, DALL·E 2 and Midjourney. They are not the only options, there are others like NovelAi or Jasper Art, but this post will focus on the main three.
The five key factors to ponder when deciding which model to use are laid out in the table below:
After deciding which model to use, the next step is learning how to use it. For Dall·E 2, it can be used on the OpenAI website. In order to use Midjourney, you need to join their Discord server which requires a Discord account.
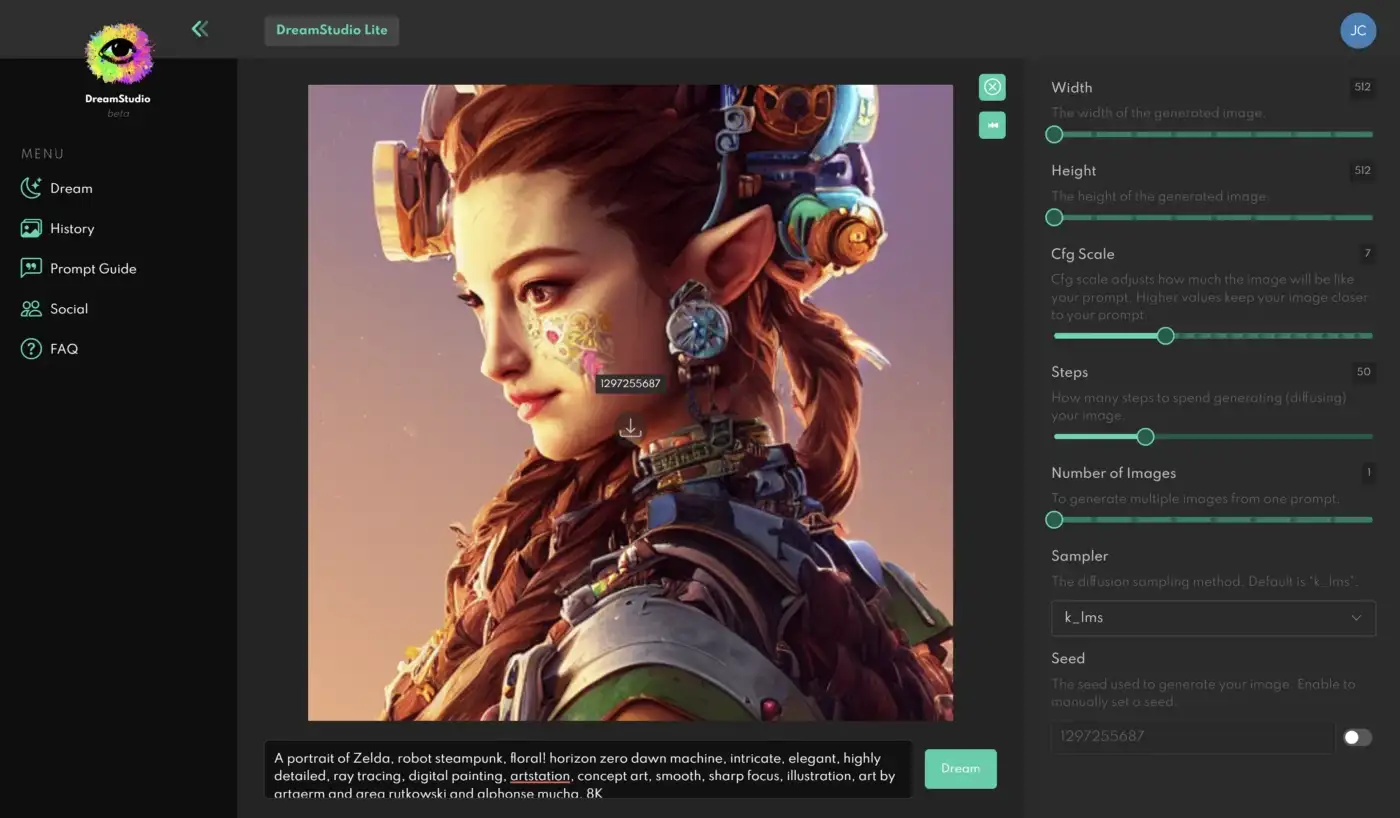
Finally, for Stable Diffusion there are three options:
- Using Dream Studio: This is the official tool, based on the web, released by StabilityAI, the company behind Stable Diffusion.
- Deploying and using the model on a personal computer: With a valid GPU of 8+ GB of VRAM, Stable Diffusion can be run on your personal computer. You can follow these steps on Reddit to get going.
- Using WebUI forks developed from the community, running on Google Colab: This is my go-to choice, as it can be run using the free tier of Google Colab and there is no need for a beefy computer. I like this Github repository that has the tooling itself and Google Colab notebooks ready to use.
Regardless of the option chosen for running Stable Diffusion, I recommend watching this Youtube video (in Spanish) where all concepts are explained in more depth, as well as exploring the subreddit from the Stable Diffusion community to look for prompts and updates on community tooling. Another place to look for prompts is Lexica Art.
Model Comparison
Now that it is clear what each of these models offers and how to begin using them, it is time for a visual comparison between the images that they generate. As part of this section, a direct comparison using the same subset of prompts is shown below. (Please note that the images shown are not mine nor Empathy.co’s. You can view the originals here.)





As shown in the images above, all three models provide high-quality results even though there are some clear differences between them. Stable Diffusion has the most inconsistent results style-wise, sometimes producing realistic results like the snow-covered mountain, while others receive a painting-like result like the Cherry Blossom image.
DALL·E 2 and Midjourney are much more consistent in their respective styles, with DALL·E 2 being the most consistent and having a style that is more suited to enterprise use. Midjourney’s style leans more towards conceptual art-like results but the quality is a bit less consistent in comparison with the results from DALL·E 2 (e.g. its Cherry Blossom image vs. the others).
What can these models be used for?
These powerful image generation models present new workflows and applications for art. For example, they can be used to generate icon-like images for programs, generate art for characters and places in tabletop role-playing games, transform video recordings, be included in current workflows for artists and graphic designers, and the list goes on.
One Last Thing…
There is an important topic to consider regarding Image Generation models (and pretty much all AI-related models): the ethical concerns that arise from these new technologies.
The conversation is mounting around how these models were trained. As noted in the Introduction, all of them were trained using huge image datasets and the images were obtained from public sources, mainly the internet. The problem is that a part of the dataset is formed by images made by artists, including copyrighted ones. That plus the fact that the AI can be guided, particularly Stable Diffusion, toward certain styles, means some images generated have a clear similarity to certain artists’ styles. Artists from all over the world have brought up the topic of plagiarism. Are the images generated by these AIs plagiarised? Is it right to use these images? The discussion is ongoing.
Another related concern is that if images can be described and generated in a matter of seconds, artists will have fewer commissions and receive less work. This is understandably concerning for visual artists, and not to be taken lightly. Controversy also arose after an AI-generated image won first place in Colorado State Fair’s fine arts competition. The decision was met with backlash and claims that the winner cheated, and regulations banning AI submissions in those kinds of competitions have been requested.
Privacy is also a matter that needs to be attended to, as a report from Ars Technica claimed that the training dataset used by Stable Diffusion contained hundreds or even thousands of private medical records. While the responsibility of filtering these images from the dataset is not clear, LAION, the company behind the dataset used by Stable Diffusion, says that they do not host these images on their servers and that filtering sensitive information is the responsibility of the companies that create these AI models. However, LAION provides the URLs for the images used in their datasets, so they are also responsible in part.
That said, enjoy your journey of creating AI-generated images while respecting the privacy and intellectual property of others!