On-Call Engineering Approach
Categories
At Empathy.co, On-Call was scheduled to allow for fast recovery in case of a disaster, errors, or loss of service. A bunch of folks from different teams are part of the On-Call rotation (with escalation policies), which guarantees that there is someone ready to catch any incidents that may occur.
We work with a "you build it, you own it" principle, which promotes each team's autonomy and ownership. Each team defines the operational challenges of their services in an Operational Readiness Review so that they can solve issues without first escalating to other teams – because nobody knows more about a service than the team that owns it.
Empathy.co’s culture enables and empowers software engineers to take ownership to build, run, and operate products and features. We actively participate in the design and implementation of customer solutions and remain responsible for the value and service they provide. This means we are engaged in the whole cycle, from software inception to any service-level management, such as debugging, troubleshooting, request and incident resolution.
Whether your organization already has an On-Call system or is looking to implement one, here's a look at how ours has been implemented and how we recommend setting it up.
Onboarding
Previously, when a new engineer was added to the On-Call rotation, there was not much guidance. To improve the On-Call onboarding, we implemented On-Call shadowing for a kinder, smoother ramp-up to going On-Call, with none of the stress or responsibility for diagnosing and fixing the issue.
The default shadowing schedule excludes weekends and the day the On-Call is transferred from one engineer to the next, resulting in a 4-days-a-week, 24-hours-a-day "shadowing shift." New engineers decide when they want to start shadowing and when they feel ready to join the On-Call rotation. Our expectation is that they begin shadowing sometime during the first three months, and our culture of shared responsibility and blamelessness makes it less daunting to make the switch from shadowing to being on call.
The Need-to-Know Steps
Identify & Log
Since it's important to respond to incidents quickly, identifying and logging must also be done quickly and methodically in order to move on to the next step.
Categorize & Prioritize
It's important to categorize incidents to prevent confusion. For instance, the number of users affected, affected services, revenue impact, etc. Prioritizing incidents can help the On-Call engineer make a call on whether or not the incident requires the time and resources of the rest of the team.
Notify the Right People
Assembling the right people at the right time and in the right place is key to ensuring exceptional mean time to resolve (MTTR) times. Therefore, it's necessary to suppress the noise and alert only the right people who can fix the alert.
Troubleshoot
It's vital that first responders like the On-Call engineer be able to troubleshoot on the go.
Our On-Call Proposal
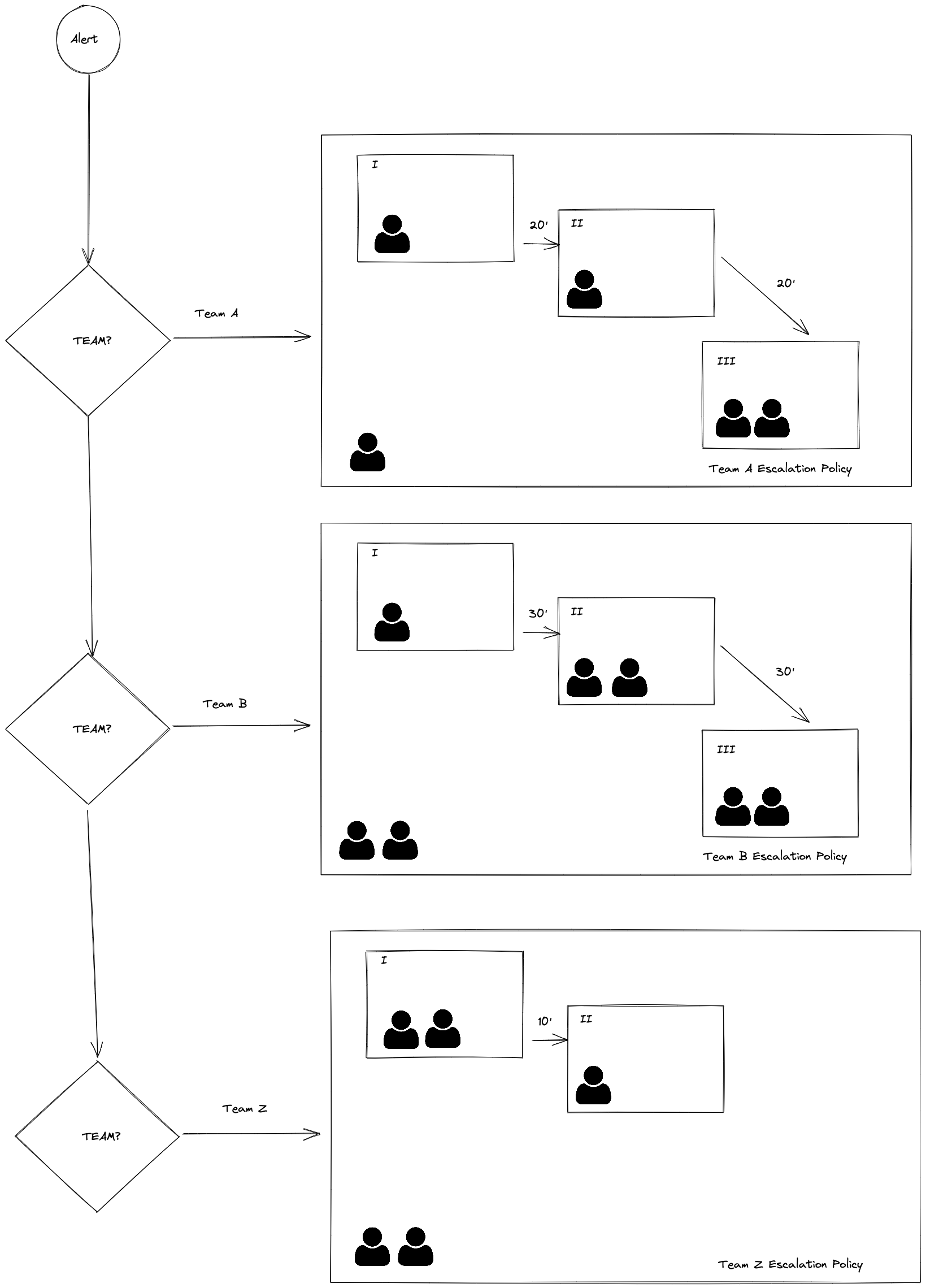
Each team is the expert regarding the workloads they have built. Following the "you build it, you own it" principle, the alerts should be owned by each respective team.
- Each team has an independent escalation policy.
- One team can escalate to another team or another backup from their escalation policy.
- The number of On-Call engineers for each escalation policy should be at least four, to avoid burnout and high-stress load.
- Escalation policies should be owned by each team. They decide if they want one member in primary, a couple in secondary, notification timings, etc.
- Alerts notify each team with the enough knowledge to solve the issue. Notifying the right people at the right time is key.
Schedule
Currently, our schedules usually start on Monday, but any weekday will do. We recommend avoiding On-Call shift changes on weekends. The shift length is one week, and only one week per month per engineer is recommended in order to avoid burnout.
Expectations
Setting clear expectations is key for maintaining alignment:
- During their On-Call shift, engineers should dedicate time to investigating and fixing the root cause of operational problems as a priority.
- Picking up new feature work should be a luxury, not an expectation.
- After a disruptive night or weekend, On-Call engineers are expected to take a break and have time to recover.
Each escalation policy should account for at least four engineers, and shift changes should happen on a weekly basis. Each On-Call engineer should plan their PTO days in coordination with their team, to ensure proper coverage.
Postmortem
After an incident happens, a Postmortem should be written the following day to detail the occurrence and the solution applied. The main owners of the postmortem are the On-Call engineers who solved the incident, but feel free to add more people to the review. The Postmortem should then be reviewed by Staff Engineering before being communicated to clients and any other stakeholders within the company.
What are the benefits of this proposal?
- Clear expectations
- Improve On-Call onboarding
- Improved team transparency and accountability in handling issues
- Suppress noise
- Better service reliability by quickly acting on and resolving alerts; alerting the right people
- Happier customers who can contact On-Call engineers for urgent issues at any time, and be assured that any issues always will be fixed quickly
- Maintaining the backup and escalation policies means everyone can provide support, if needed
This is the On-Call approach that works for us, but each organization is different. It's important that you create an approach that fits your company's needs, offers reliability for your clients, and balances the workload for your On-Call engineers.