
Ramiro Álvarez
I’m a Staff Platform Engineer at Empathy.co. I mostly manage Kubernetes Clusters, CI/CD orchestration, Elasticsearch, MongoDB and try to break things on AWS, GCP and Azure.
On-Call Engineering Approach
At Empathy.co, On-Call was scheduled to allow for fast recovery in case of a disaster, errors, or loss of service. A bunch of folks from different teams are part of the On-Call rotation (with escalation policies), which guarantees that there is someone ready to catch any incidents that may
Progressive Delivery: Argo Rollouts Adoption
Introduction
Progressive Delivery is emerging as a worthy successor to Continuous Delivery, by enabling developers to control how new features are launched to end users. Its wide popularity is owed to the demand for faster and more reliable software releases. The increasing emphasis on customer experience has begun to push

Progressive Delivery in Kubernetes: Analysis
Overview
In this post, an analysis of Progressive Delivery options in the Cloud Native landscape will be done to explore how this enhancement can be added in a Kubernetes environment. The most embraced tools from the Cloud Native landscape will be analyzed (Argo Rollouts and Flagger), along with some takeaways
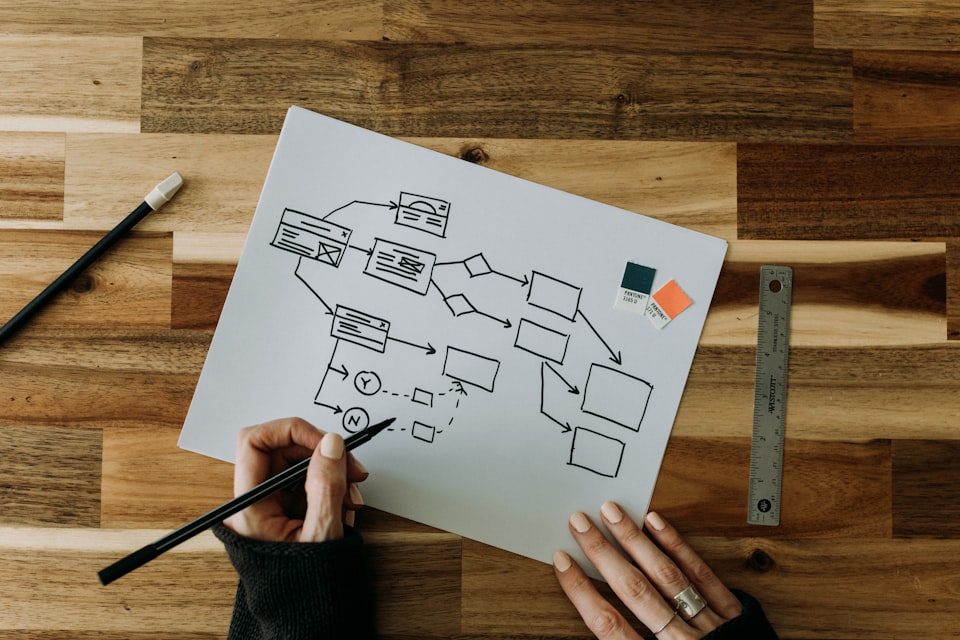
Collaborative Architecture Diagrams
Motivation
Architecture diagrams should be visible to everyone in the company, as Trust is
one of our principles here at Empathy.co. Ensuring visibility would ensure we
have a single source of truth where changes can be tracked and revisions can be
made. It would also align Engineering, Growth, and
Cloud FinOps – Part 5: Usage Report
Wrapping up this series, following our previous Cloud FinOps - Part 4: Kubernetes Cost Report, this final piece looks at how to increase visibility of underutilized workloads.
Cloud FinOps - Part 4: Kubernetes Cost Report
This blog post is a continuation of Cloud FinOps - Part 3: Cloud Cost Report
[https://medium.com/empathyco/cloud-finops-part-3-cloud-cost-report-865a81c03c1c]
, in which we will explore how to gain cost visibility on Kubernetes Workloads.
Motivation
Nowadays, a lot of companies run their workloads on Kubernetes because there are
many benefits to
Cloud FinOps - Part 2: Tag Allocation Strategy
In the first post
[https://engineering.empathy.co/cloud-finops-part-1-principles/] of this
four-part series, we explored the Cloud FinOps principles and the key milestones
in the journey to start walking in FinOps:
* Tag Allocation Strategy
* Cost Report
* Usage Report
In this post, we’ll dig deeper into a crucial step in