Cloud FinOps – Part 5: Usage Report
Categories
Wrapping up this series, following our previous Cloud FinOps - Part 4: Kubernetes Cost Report, this final piece looks at how to increase visibility of underutilized workloads.
Introduction
You pay for the resources you deploy, whether you use them or not. When you're running at scale in the cloud, it’s not uncommon to have underutilized resources or even some that you have completely forgotten about!
It may seem pretty simple, but it can be challenging to know which resources need to be reviewed since doing so requires teams to have the right tracking metrics. FinOps can help organizations set a common workflow, provide utilization visibility and last but not least, detect areas for improvement as a result.
The main goal is to increase the visibility of underutilized resources, in order to reduce costs and expand the FinOps cultural shift to strategically spread utilization metrics and stretch them further.
Workflow
Visibility
Most of the time, teams' capacity requirements are not fully known, perfectly defined, or well understood. Therefore, overprovisioned resources are a frequent occurrence aimed at ensuring there is no lack in performance. It’s not a bad thing, but it’s also not ideal. The optimal way to benefit from working in the cloud is to create the ability to quickly make adjustments along the way.
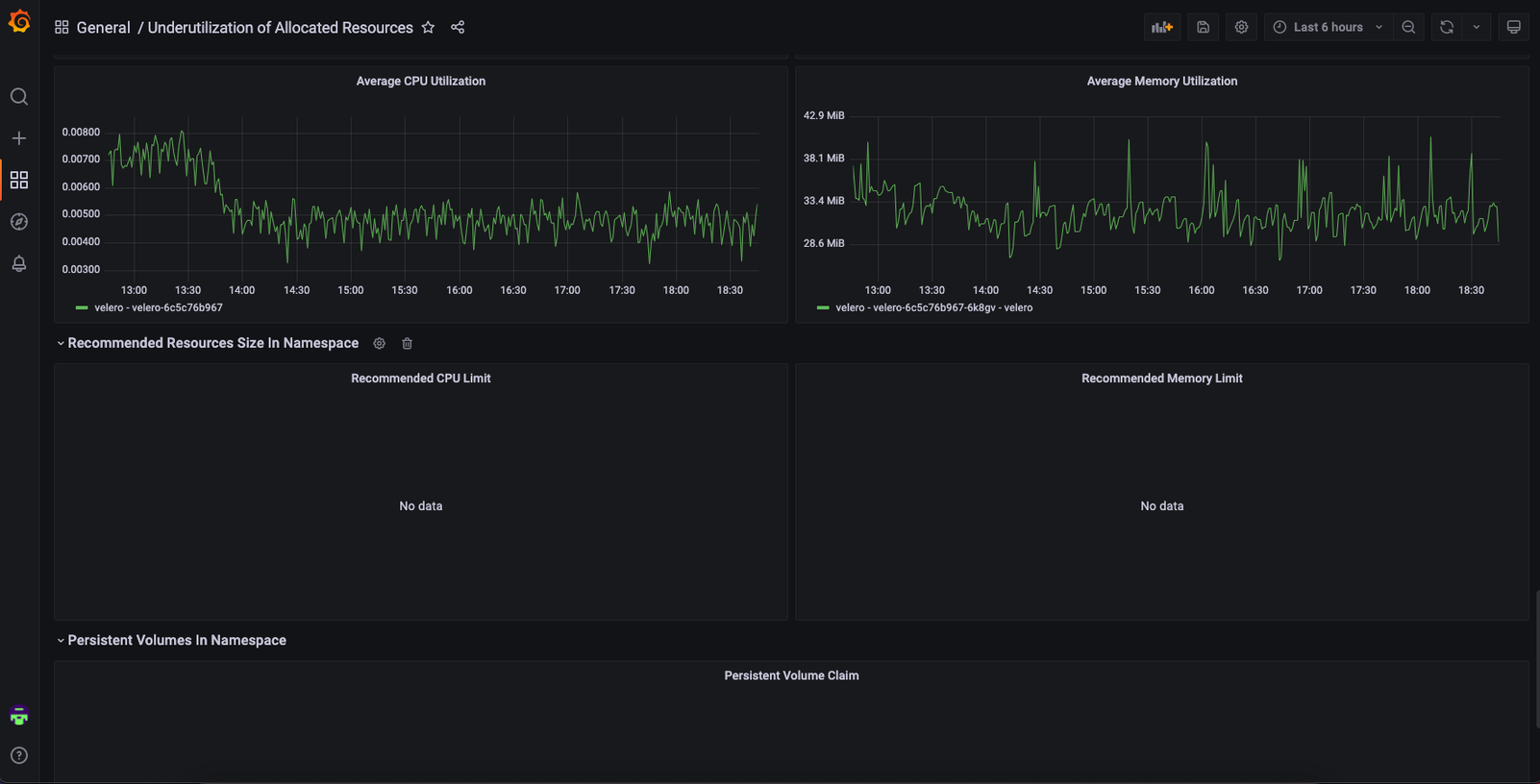
At Empathy.co, our workloads are running over Kubernetes, so our main goal is to increase visibility of its utilization.
To do this effectively across teams, we use the same monitoring stack that is used for the rest of our workloads. In this case, Prometheus-Grafana will be used to provide visibility and show teams where waste is occurring.
You can find the Grafana Dashboard here:

Underutilization of Allocated Resources dashboard for Grafana | Grafana Labs
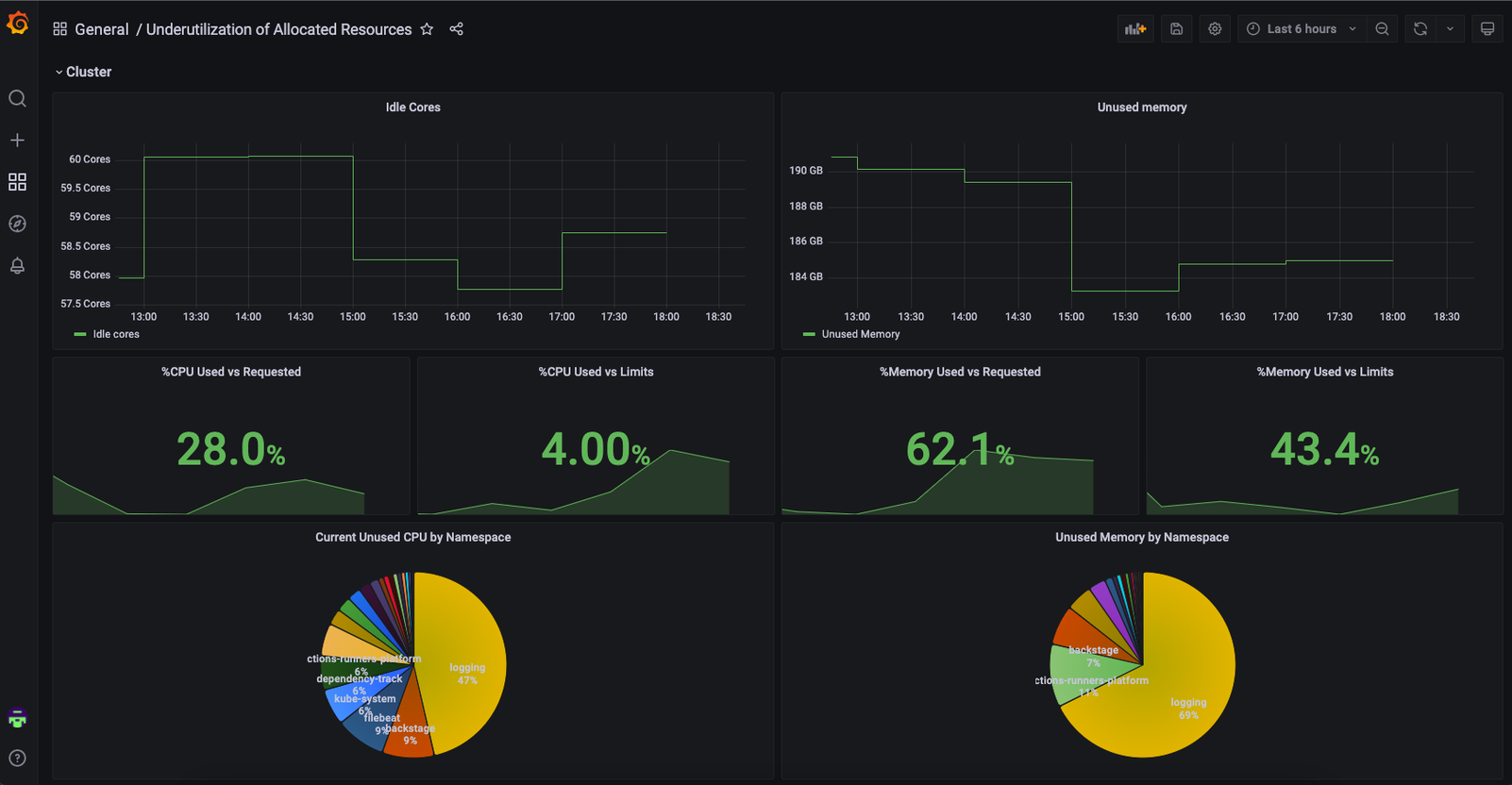

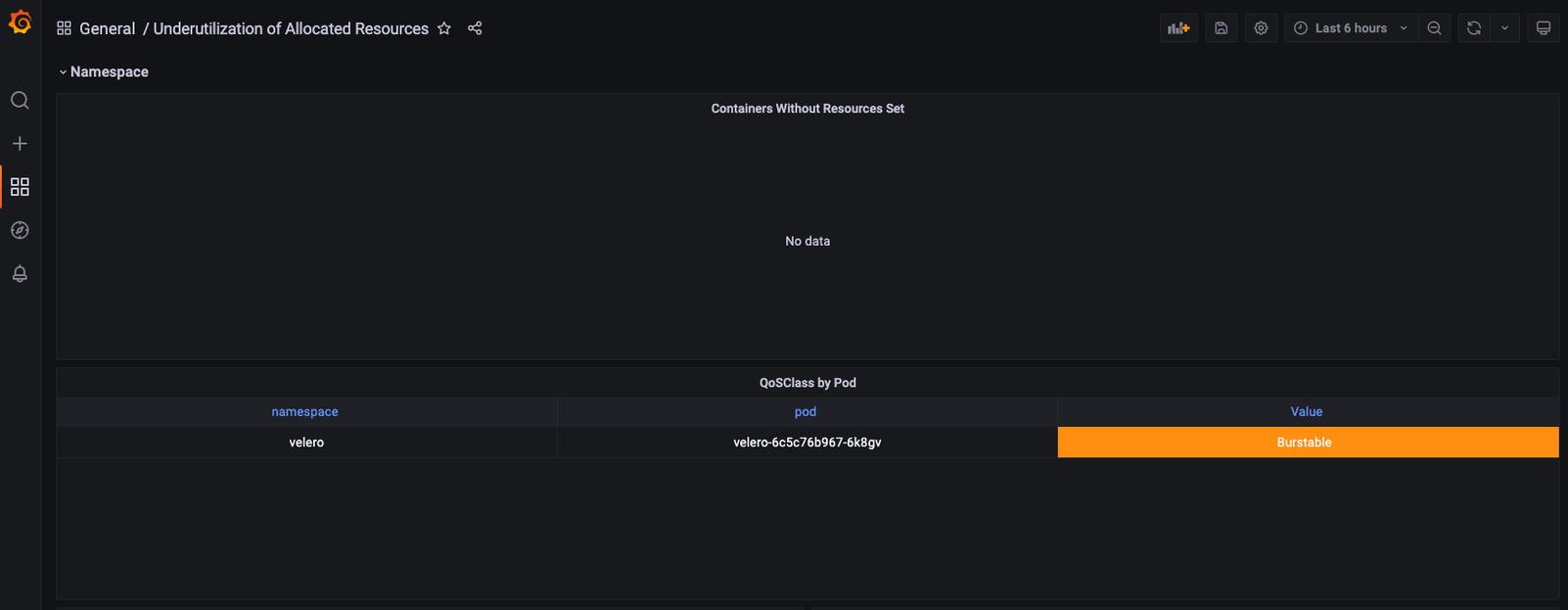
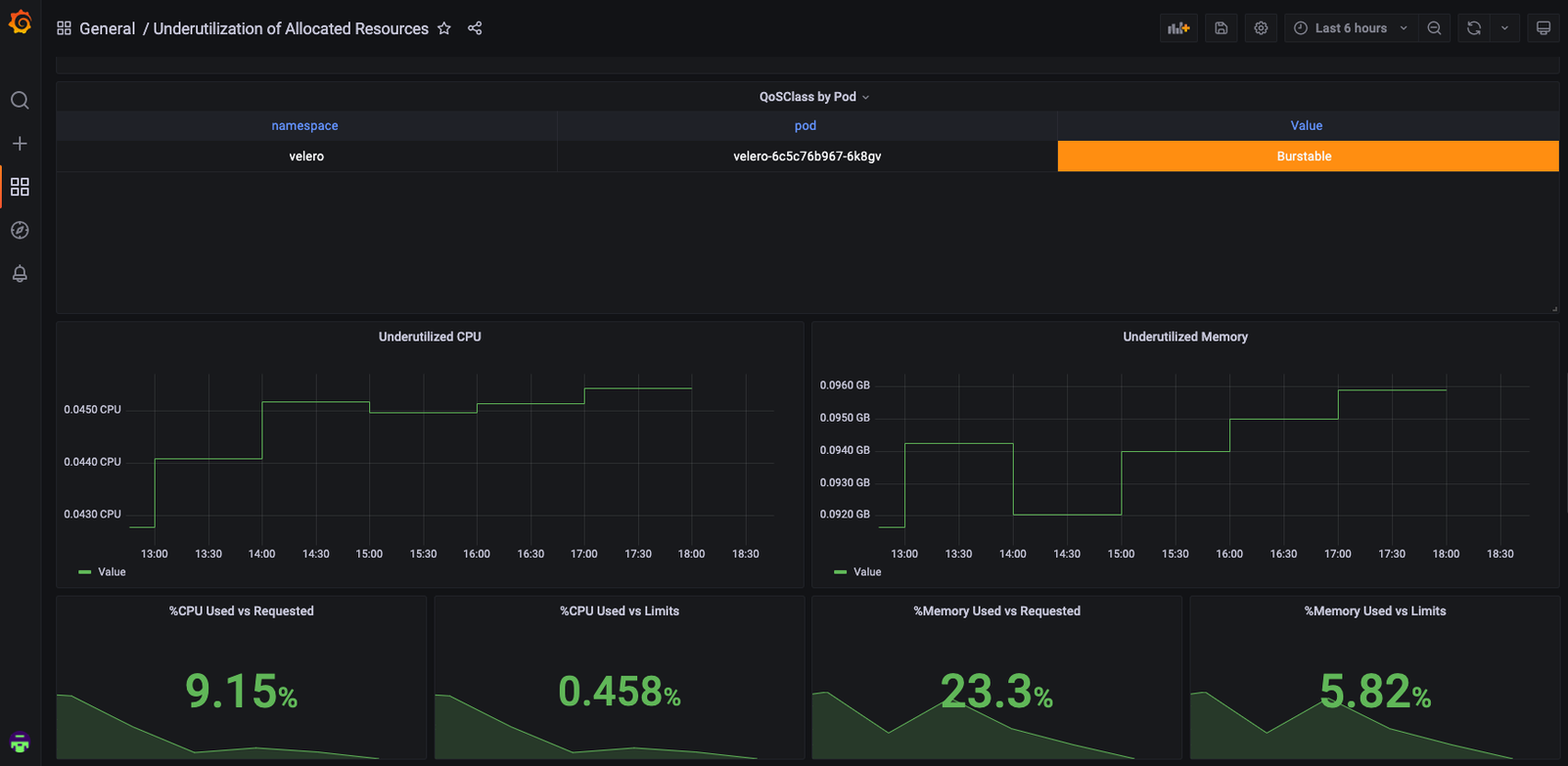
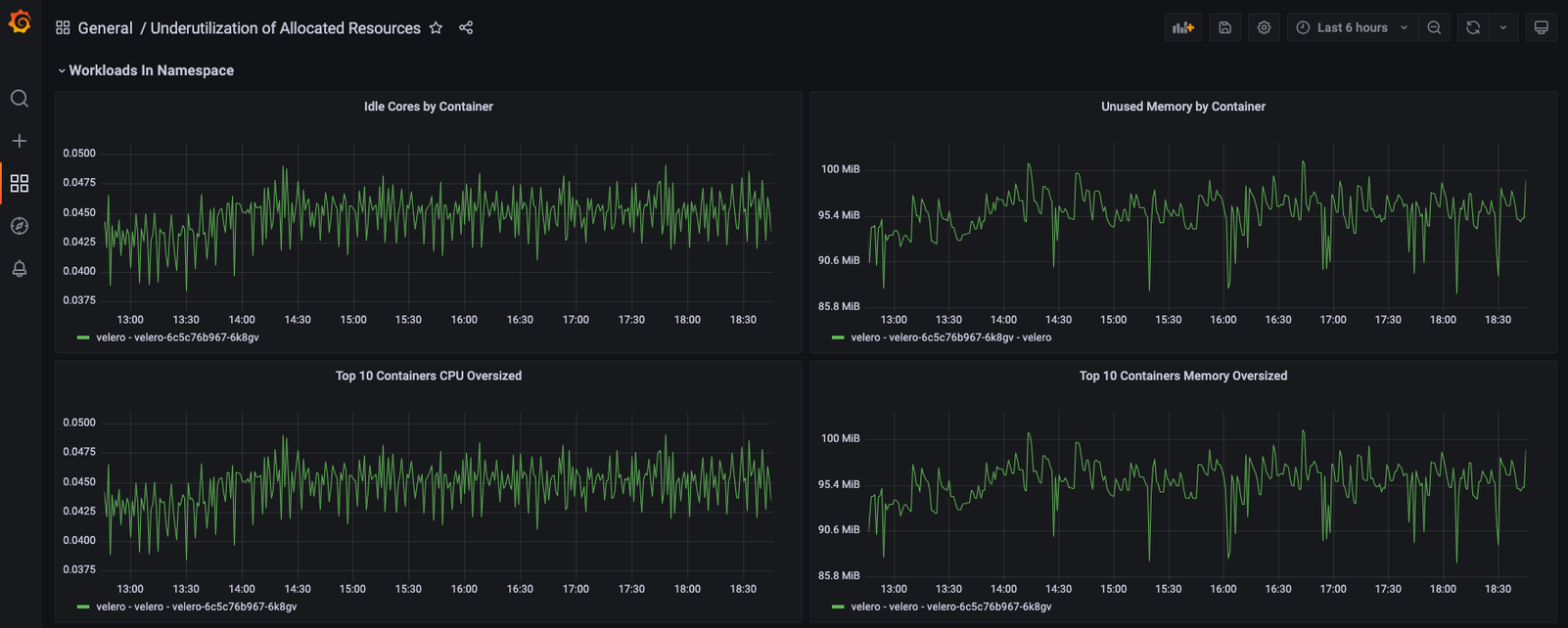
Usage Reduction
There are multiple ways to reduce usage. Now, usually, cutting the size of a resource in half equates to halving the cost. But when it comes to reducing usage at scale, a cultural shift is required. The most common ways to reduce usage include:
- Deletion: It is likely that some teams have forgotten about a series of resources that they are not using. In some cases, removing a simple unused resource can save 100% of the associated cost.
- Rightsizing: At the start of a project, the resources are overprovisioned to speed things up. As the project evolves, the workload should do the same; adjust the usage requirements and avoid workloads with 1% CPU usage.
- Re-architecture: Sometimes, performance issues are prevented by scaling up resources. But eventually, the costs typically begin to outweigh the benefits or there is no way to scale up. When this situation arises, a workflow re-architecture is necessary, in order to use more cloud-native approaches, opt for cheaper cloud services, and reduce the overall operative cloud cost.
Takeaways
- Usage reports are the common source of truth across all teams.
- Providing teams with visibility of resources lets them know where waste is occurring and, subsequently, offers perspective on how to avoid it.
- Teams should determine whether or not to maintain resources based on their respective utilization metrics.
What comes next?
Now that you know how to gain visibility of your Kubernetes cluster usage and are familiar with the associated benefits of adopting Cloud FinOps practices as you handle your workloads, where do you go from here? You take the time to share what you’ve learned and the effect it has had on your team’s operations
- Cost Savings: Show your team the financial benefit of having adopted a Cloud FinOps strategy
- Increased Sustainability: Explain the impact of savings, as it relates to your team’s carbon footprint
As our Cloud FinOps series comes to a close, the entire Empathy.co team hopes that the steps, approaches, and guidelines laid out have led you and your team to successfully implement these principles (or get ready to)!