Moving to a mono-repo: Part 1, The Journey
Categories
Often the journey can teach you a lot about your destination. For many years, Empathy.co has been working on web frontend projects. Along the way, we’ve created lots of libraries to solve different kinds of problems.
However, while we are happy to be able to reuse code between different projects, we realised that having every library in its own repo was not efficient. It was slowing us down. It was time for a big change.
In this two-part blog series, I’ll share Empathy’s experience moving to a mono-repo — both the journey (challenges faced) and the destination (successful migration).
Previous workflow
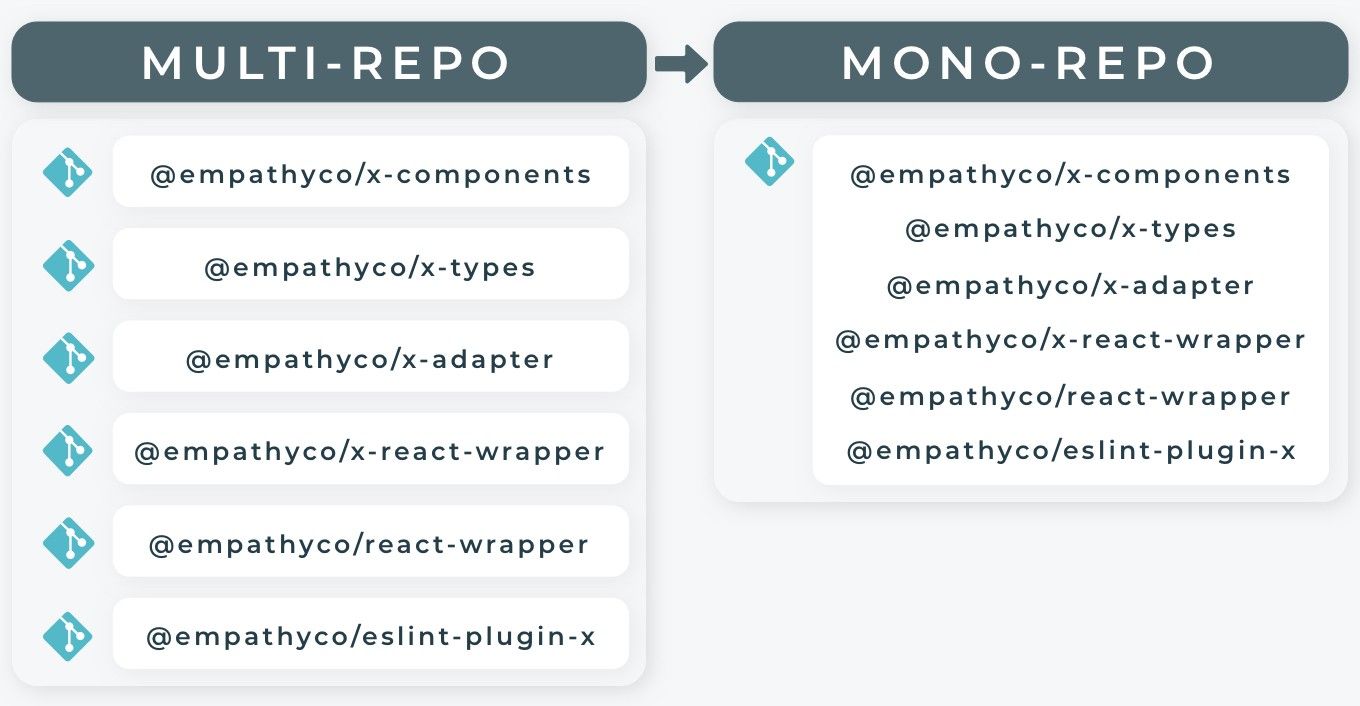
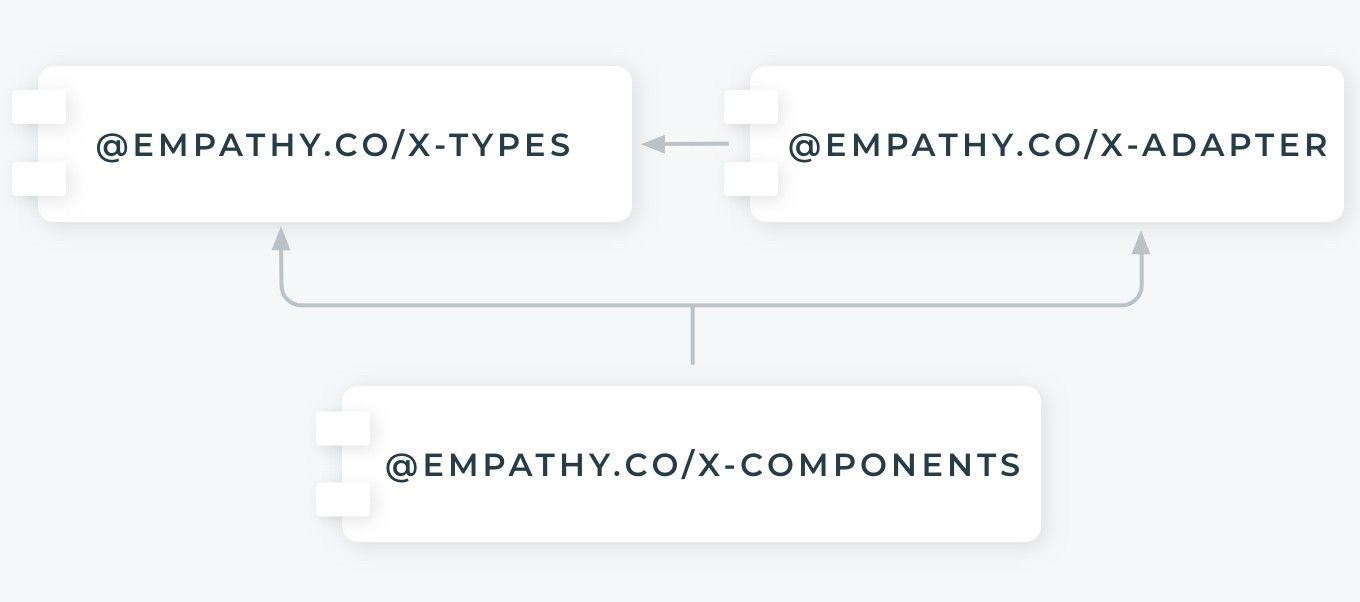
Let’s say that we are developing a feature for our main package, the X Components. This library has two main dependencies: the X Adapter and the X Types.
X Components is a Vue library that allows developers to easily create a search application with components that smartly interact between themselves.
The X Adapter is a package that serves to communicate with an API and translates its domain model into one that the X Components can understand.
Finally, the X Types is the project that contains the X Components domain model. Just a bunch of types and types guards to help us write type-safe code.
In a dependency diagram, these modules look like this:
Developing a new feature implies changing these three packages, following a sequential approach:
The first project to develop the feature in is the one that has no dependencies. In this case, X Types. Once the code is written, and a pull request created, validated, and merged, we can start with the adapter changes.
Now, the developer of this feature has to download the types project latest changes, compile them, and locally install them somehow. Here we tried NPM linking, but we always struggled with duplicated dependencies due to how the node modules resolution system works. So we decided to just pack our local builds with NPM pack and install the generated tarball file in the projects that we needed. Then the developer can start working on their task and submit a pull request upon finishing. Their teammates will review it, and merge it once it is fine.
Finally, we can develop the needed changes in the X Components project. Download both projects, build them, do a local install of both, develop the changes, submit a pull request and merge it.
This was just a simple example with only some of the projects that we usually work with. The more projects you have to work on, the bigger the issues are. Let’s take a look at some of them.
Slow development
All the previously mentioned steps created friction for us. Features were developed in a sequential way; we couldn’t parallelise working in different packages at the same time.
Even if we did so, and the same person developed the changes in all the needed packages, opening multiple pull requests at the same time, this was still slow as the reviewers had to keep playing with local installs, multiple branches and multiple projects.
Handling dependency versions
Handling dependency versions was not easy either. We use TypeScript in every project. If we have 10 projects, having to create 10 pull requests just to bump up this version isn’t fast.
Moreover, because we are humans, we may forget things. When doing these dependency upgrade changes, we often forget about our smaller packages, until someone did an analysis of the build of the project and found duplicated dependencies.
Versioning our projects
We have tried different approaches for versioning our projects. Initially, we discussed which version a package should be bumped to in the stable release branches. We reviewed the committed code and decided if it should be a major, minor or patch version change.
This was error-prone, slow and inconsistent. So we decided to give this responsibility to the developers of each pull request. When a pull request was submitted, the developer had to update the version of the project with a pre-release tag, bumping the number up to what they thought may be correct. This wasn’t a good idea either, as every pull request ended up with comments like ‘fix package.json and CHANGELOG.md conflicts please’.
Finally, we discovered Conventional Commits and Standard Version. Standard version is a library that automates versioning projects and keeps track of the changes in a markdown file. It does so by reading the commits of the repository, which must be written using the Conventional Commits format. With this we just have to be careful when merging the pull requests, adding a proper commit message. Then in the release branches by simply executing a command, the project version is updated and a new entry in the change-log is generated. This was something that worked really well for us, ending the discussions and solving our problems related to versioning.
Breaking changes
Sometimes we have to introduce breaking changes to the API exported by one of our packages. These changes are usually part of a bigger feature, and often, the developer who introduced the breaking change only has their scope touching a few projects. They wouldn’t realise that by introducing that breaking change, they are breaking another dependent package.
This other package will be fixed in the future, possibly by another developer who probably won’t 100% understand the breaking change if they weren’t involved in the task, neither as a pair programming mate nor as a reviewer. They will have to spend some time maybe asking the developer who introduced the breaking change, or figuring out a solution.
Releases
Libraries had to be released one by one. You release a package, then you update all of its dependents. You release the next one, and you update all of its dependents…
Following the previous example, this meant releasing first the project without dependencies, X Types. Then updating and releasing the X Adapter, and finally the X Components one. If you have to release a library that is used by 5–6 or more projects… I bet you can feel our pain!
Finding a solution
But in fact, these issues alone were not the turning point for us — the moment that truly made us reconsider if our current work model could be improved. The key factor to rethinking our workflow and the structure of our repositories was transforming our projects into open source ones.
At Empathy, we want to support open source. If our code relies on open source libraries, why not try to give something back to the community? Just opening our repositories to the public with the old approaches wouldn’t work. The way they were structured didn’t help anyone to understand the code, and let’s not talk about public pull requests. It was way far too complex to expect any developer to set up a local development environment, and open a pull request.
Additionally, because projects were created at different times, by different people, with different knowledge, experience or opinions, each one of them was using their own tools for the build, for linting, for testing, different conventions… Again, if we want to facilitate understanding for anyone to contribute to these projects, it makes sense to try to homogenise the projects, making them as similar as possible to work with.
Knowing the problems we wanted to solve and taking inspiration from the open source community, a mono-repo seemed like it could help us. Indeed, as I’ve just said, many popular open source libraries use mono-repos to manage all dependencies; so we decided to try this new organisation system.
The first step was to choose a tool to handle the mono-repo. There are many possibilities: Yarn, Pnpm, Lerna, or even TypeScript supports something similar through project references. I’m not here to discuss which one is the best, the fastest, or the one using less memory. They are all awesome tools supported by the open source community.
Lerna was our chosen option. It’s a tool designed to facilitate working with mono-repos. This is not a small feature of it — mono-repos are the reason Lerna was born. Because of this, it provides several utilities to help work with them: running commands in every package, importing git repositories, versioning projects with different strategies, publishing, keeping change-logs for each project, linking packages between themselves, hoisting dependencies.… Lots of options that we soon fell in love with.
So this was our journey to uncovering a promising solution: move to a mono-repo and go open source with Empathy’s Interface X Components. Spoiler alert, it worked! But not before facing more challenges to reach our goal. Stay tuned for Part 2: The Destination.