Progressive Delivery: Argo Rollouts Adoption
Categories
Introduction
Progressive Delivery is emerging as a worthy successor to Continuous Delivery, by enabling developers to control how new features are launched to end users. Its wide popularity is owed to the demand for faster and more reliable software releases. The increasing emphasis on customer experience has begun to push Continuous Delivery methodology by the wayside. Large enterprises like Netflix, Amazon, and Uber are turning to Progressive Delivery to test and release code in a phased and controlled manner.
In a nutshell, Progressive Delivery empowers developers to plan and implement code changes to a subset of users and then expand it to all users. The progressive rollout of features is executed through techniques like blue-green deployment, feature flagging, and canary deployments. You can mitigate issues that come up by promoting a version to all users only when you’re confident that it is performant and reliable. And if it fails in production, the impact radius is restricted to a subset of users, and the update can be rolled back immediately.
Toolkit for Progressive Delivery
Apart from laying the foundation with Kubernetes, GitOps, service mesh, the key piece to the entire puzzle is a purpose-built progressive delivery tool.
Argo Rollouts is a Kubernetes controller and set of CRDs which provide advanced deployment capabilities such as blue-green, canary, canary analysis, experimentation, and progressive delivery features to Kubernetes.
We have also performed a deep analysis of the solution chosen at Empathy.co, outlining the requirements, benefits and a comparison between Argo Rollouts and Flagger.
Progressive Delivery Strategy
Progressive Delivery can be implemented through a number of strategies:
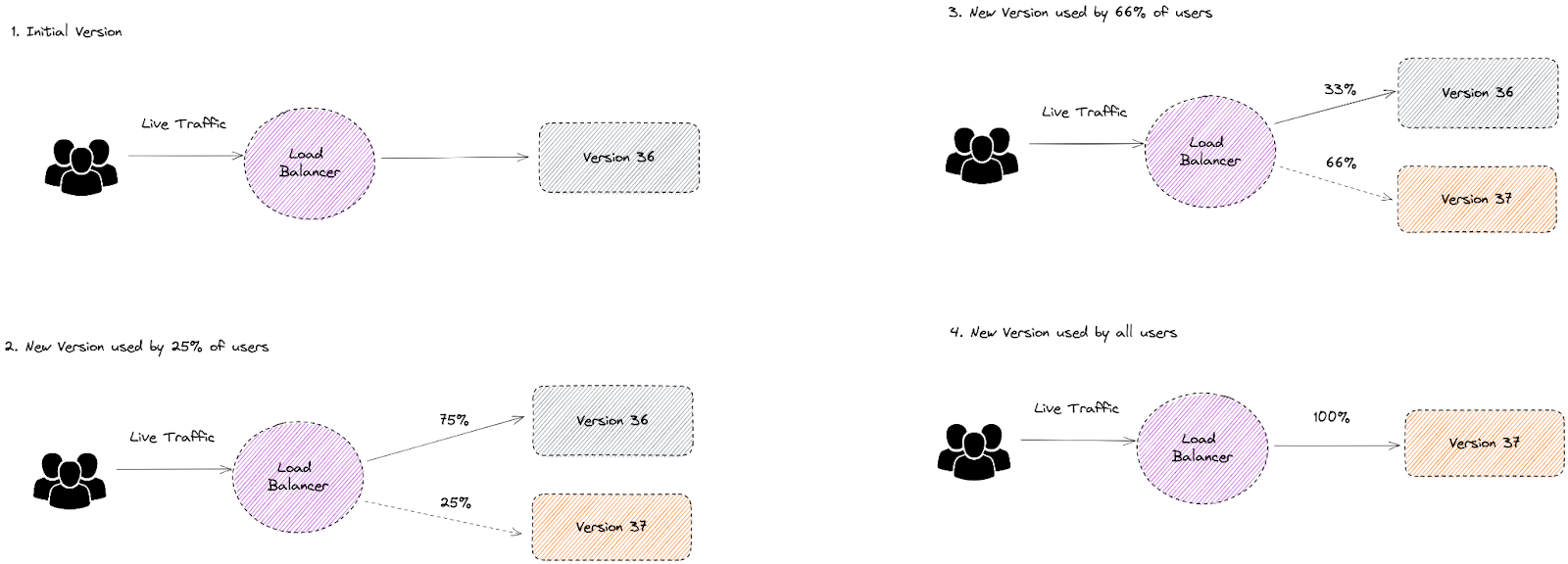
Canary Release
Channel a limited amount of traffic to a new canary service, and then if it passes reliability tests, you can gradually shift all traffic from the old to the new service, and the canary becomes the default version.
Feature Flag
Control the code launch remotely through a toggle-like feature, which enables changes to be rolled back immediately in the event of a failure.
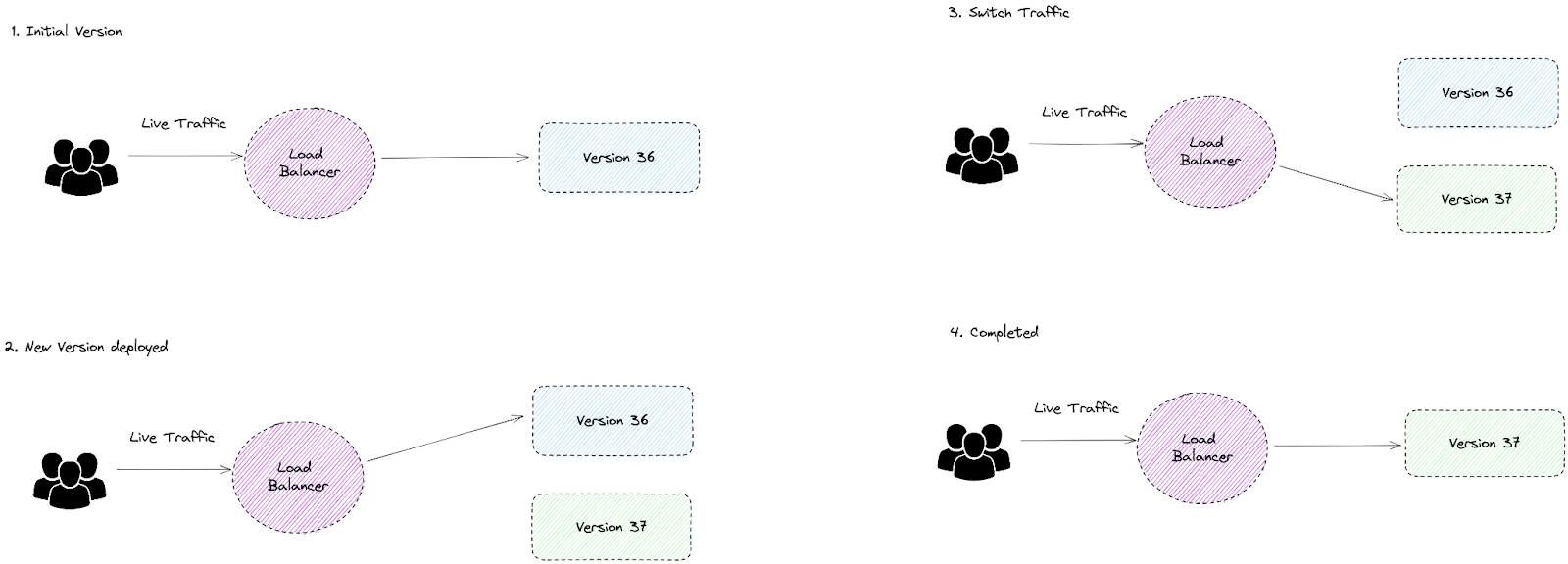
Blue-Green Deployment
Gradually transfer traffic from an existing application (blue) to a newer one (green), while the blue version acts as a backup.
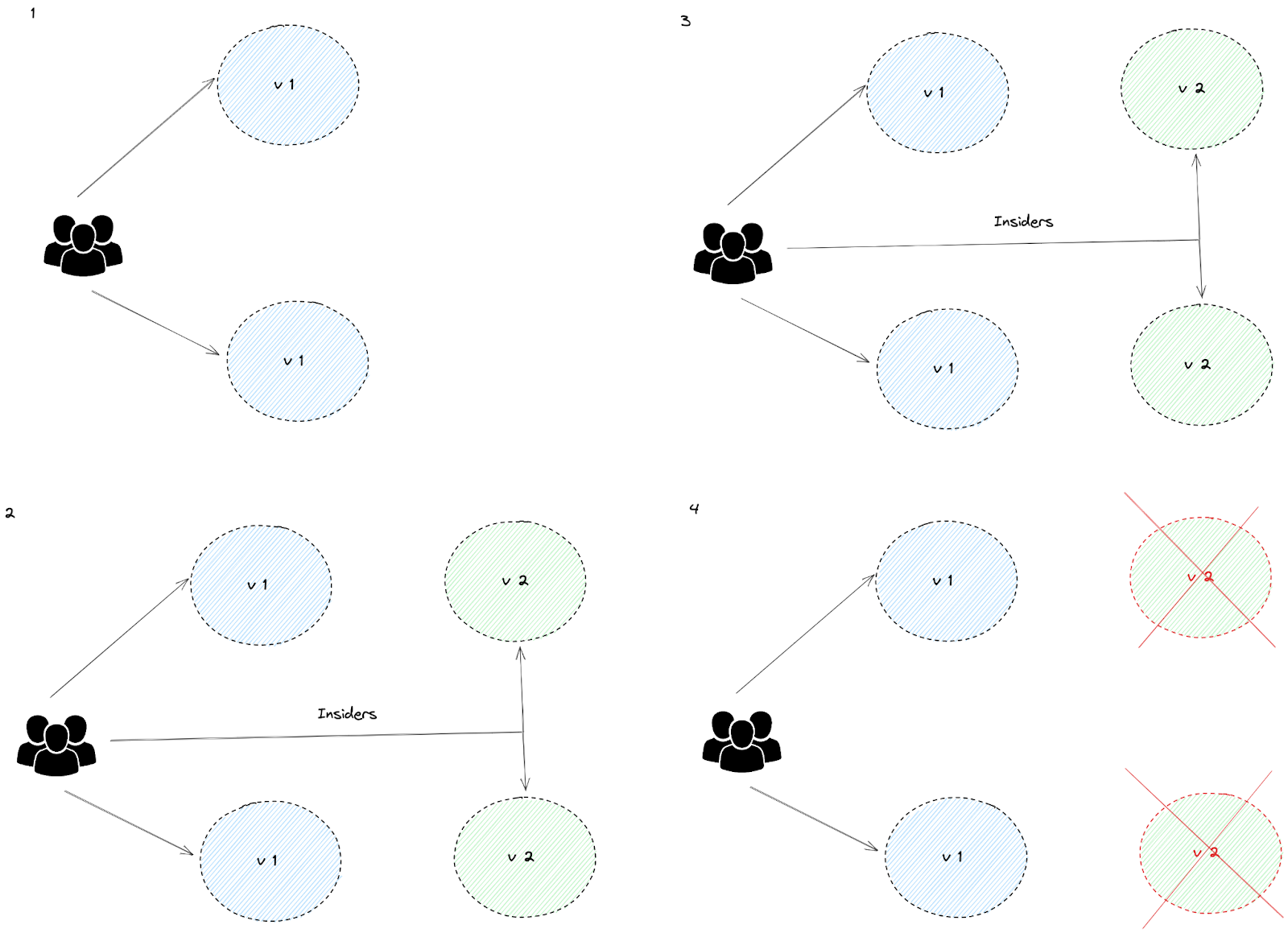
A/B Testing
Expose two different categories of the audience to two different application versions and analyze their performance to decide which is the ideal version.
Which tactic you pick depends on your goals and which you think would fit your workloads best.
Custom Strategy
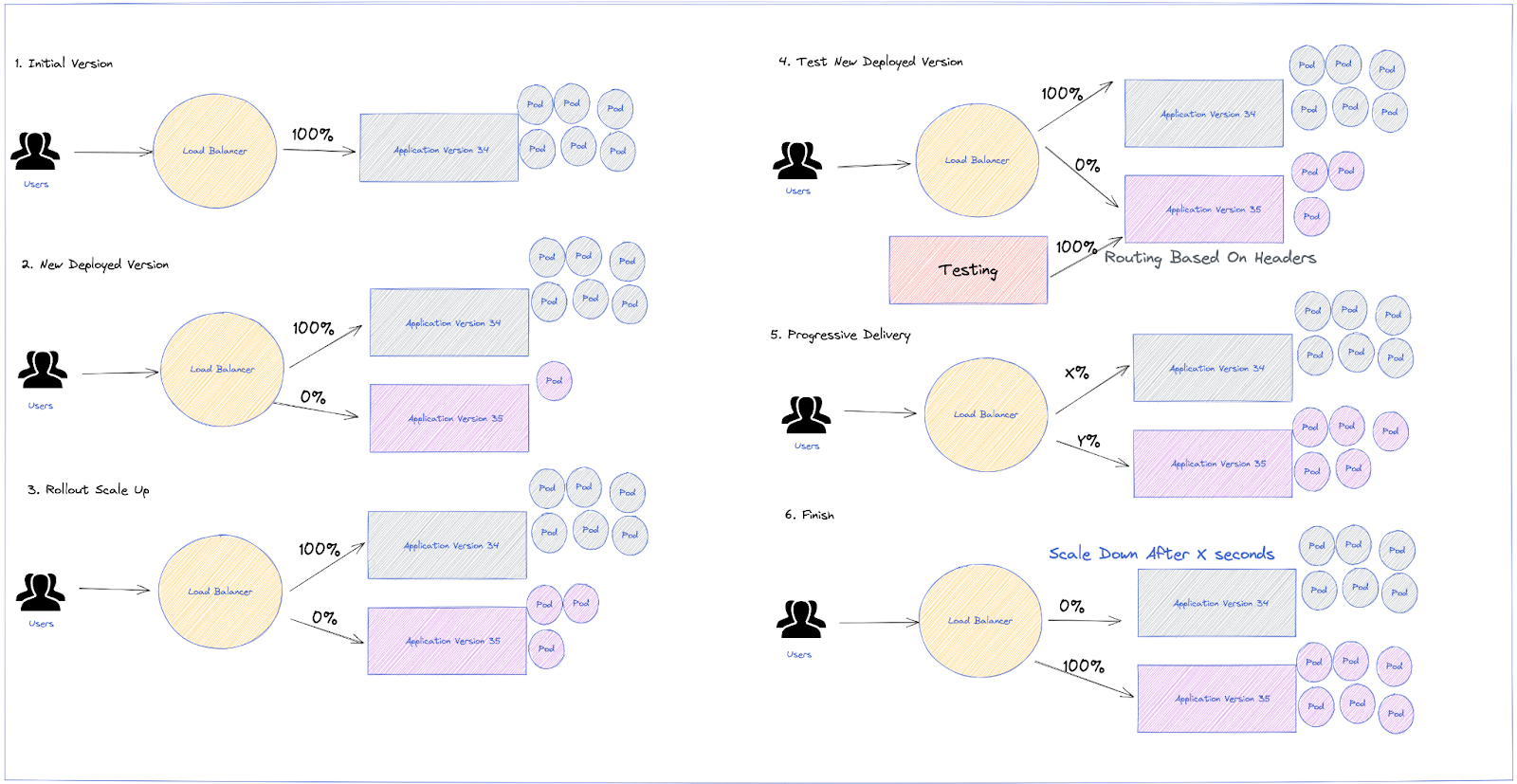
Although those are the basics methods, Argo Rollouts allows more custom analysis to be added and all the capabilities to be explored, making it possible to create our own strategy during Releases. For instance, a custom strategy with the following capabilities could be defined:
- Scale the canary stack up for testing purposes
- Set some header-based traffic shaping to the canary while
setWeightis still set to zero - Begin testing and then, when the tests are OK, start the canary promotion
- Canary promotion sends traffic gradually
- Automated rollback in case SLO and Error Budget is burnt out based on analysis from Prometheus Metrics
- Scale down the old application release after a while, in order to guarantee a faster rollback in case of failures; no need to scale up the previous version
Outline the Metrics You Want to Measure
With Progressive Delivery, you can reduce risk. This is mainly because you continuously test code changes, analyze performance and implement your learnings all in real time. To ensure that this happens seamlessly, it's important to have KPIs against which to measure the success of your release. In our case, the SLO metrics would be a good KPI to choose. Thanks to Pyrra, there is a set of Prometheus Rules to monitor the Error Budget of your application and send an alert in case it is close to being burnt out.
Those metrics can be added as part of the Analysis in Argo Rollouts, so be sure to pay attention to how to explore Prometheus metrics in the Analysis and that your metrics make sense for checking the success of your release.
Check your Pyrra configurations, as they will be propagated as Prometheus Rules and will create some critical alerts for the Error Budget.
Migration: From Deployment to Rollout
There are multiple ways to migrate to Rollout, but here we'll explain the simplest one:
- Reference an existing Deployment from a Rollout using the
workloadReffield.
During the migration, the Deployment and the Rollout should coexist to avoid downtime. After that, the Deployment resource can be scaled down to zero replicas.
A temporal ingress and service will be located to avoid downtime and ensure correct behavior during the migration, because rollouts introduce a hash label in the selector to route the traffic.
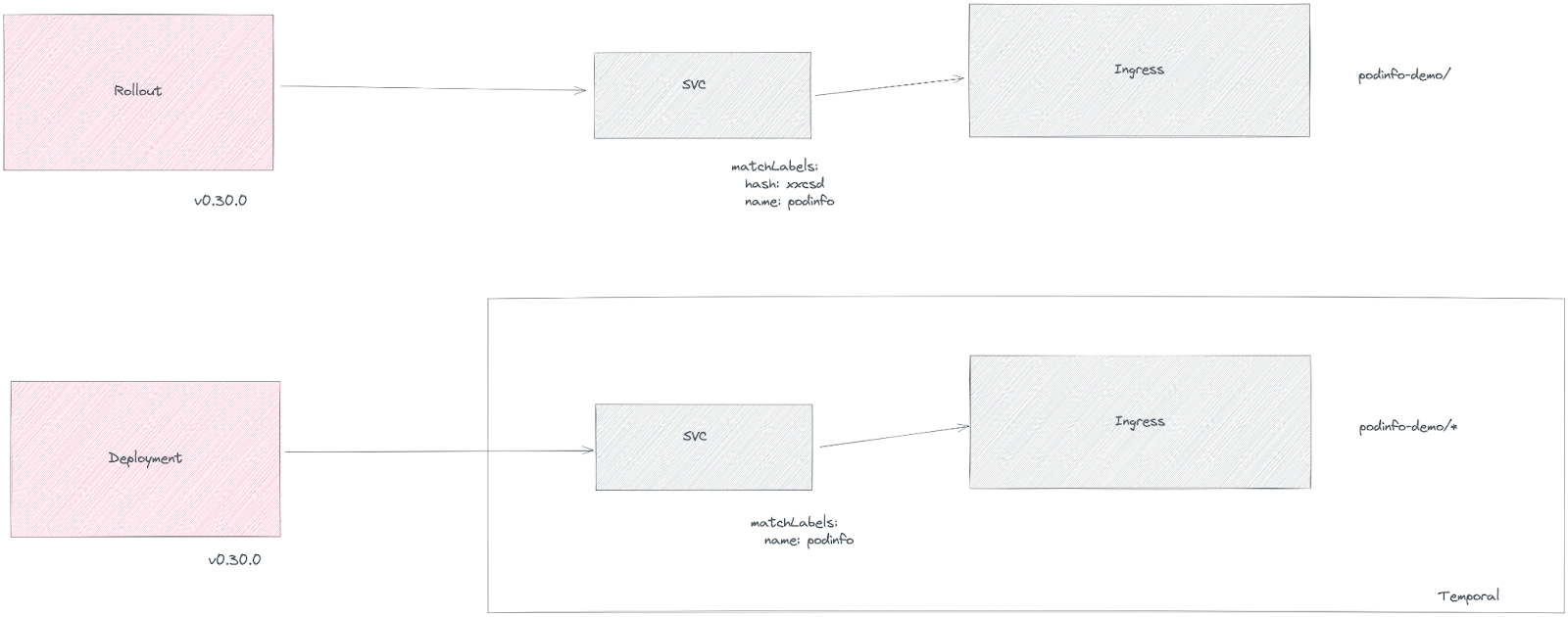
After the migration, the temporal service and ingress can be deleted.
Kubectl Plugin
Argo Rollouts offers a Kubectl plugin to enrich the experience with Rollouts, Experiments, and Analysis from the command line.
Troubleshooting Argo Rollouts
Rollouts
Q: Can I restart a Rollout?
A: Sure, you can restart a Rollout just like you can restart a Deployment. There are multiple ways to do so: using the kubectl plugin, directly from Argo Rollouts UI, or through the Argo CD UI.
Q: Does the Rollout object follow the provided strategy when it is first created?
A: As with Deployments, Rollouts do not follow the strategy parameters on the initial deploy. The controller tries to get the Rollout into a steady state as fast as possible by creating a fully scaled-up ReplicaSet from the provided .spec.template. Once the Rollout has a stable ReplicaSet to transition from, the controller starts using the provided strategy to transition the previous ReplicaSet to the desired ReplicaSet.
Rollbacks
Q: If I use both Argo Rollouts and Argo CD, won't I have an endless loop in the case of a Rollback?
A: No, there is no endless loop. As explained in the previous question, Argo Rollouts doesn't tamper with Git in any way. If you use both Argo projects together, the sequence of events for a Rollback is the following:
- Version N runs on the cluster as a Rollout (managed by Argo CD). The Git repository is updated with version N+1 in the Rollout/Deployment manifest.
- Argo CD sees the changes in Git and updates the live state in the cluster with the new Rollout object.
- Argo Rollouts takes over as it watches for all changes in Rollout Objects. Argo Rollouts is completely oblivious to what is happening in Git. It only cares about what is happening with Rollout objects that are live in the cluster.
- Argo Rollouts tries to apply version N+1 with the selected strategy (e.g. blue-green).
- Version N+1 fails to deploy for some reason.
- Argo Rollouts scales back again (or switches traffic back) to version N in the cluster. No change in Git takes place from Argo Rollouts.
- The cluster is running version N and is completely healthy.
- The Rollout is marked as "Degraded" both in ArgoCD and Argo Rollouts.
- Argo CD syncs take no further action as the Rollout object in Git is exactly the same as in the cluster. They both mention version N+1.
Q: How can I run my own custom tests (e.g. smoke tests) to decide if a Rollback should take place or not?
A: Use a custom Job or Web Analysis.
Analysis
- What is the difference between failures and errors?
- Failures are when the failure condition evaluates to true or an AnalysisRun without a failure condition evaluates the success condition to false. Errors are when the controller has any kind of issue with taking a measurement (i.e. invalid Prometheus URL).
For more information, check out the Argo Rollouts FAQ.
Takeaways
ArgoRollouts offers enhancements to the usual Kubernetes deployment strategies, and the main highlights of adoption are:
- Ability to choose your strategy and select the one that best suits your needs
- No need to adjust to canary or blue-green, because Argo Rollouts allows you to create a custom strategy
- Special attention to migration from Deployment to Rollout with some caveats that must be taken into consideration.