Progressive Delivery in Kubernetes: Analysis
Categories

Overview
In this post, an analysis of Progressive Delivery options in the Cloud Native landscape will be done to explore how this enhancement can be added in a Kubernetes environment. The most embraced tools from the Cloud Native landscape will be analyzed (Argo Rollouts and Flagger), along with some takeaways and the selection that best fits Empathy.co’s needs.
Motivation
The native Kubernetes Deployment Objects supports the Rolling Update strategy which provides a basic guarantee during an update, as well as limitations:
- Few controls over the speed of the rollout
- Inability to control traffic flow to the new version
- Readiness probes are unsuitable for deeper, stress or one-time checks.
- No ability to check external metrics to verify an update
- No ability to automatically abort and rollback the update
For the reasons above, in a complex production environment, this Rolling Update could be risky because it doesn't provide control over the blast radius, may roll out too aggressively and there is no rollback automation in case of failure.
Requirements
Although there are multiple tools that offer multiple deployment capabilities, the minimum requirements would be:
- GitOps approach: The tool chosen should work under GitOps approach, no manual changes required
- NGINX Ingress Controller compatibility: The goal is to add more deployment alternatives, not to research a different Kubernetes ingress controller
- Prometheus analysis compatibility: The metrics are saved on Prometheus, the tool should allow using Prometheus queries to perform a measurement.
- Compatible with multiple Service Mesh options: The chosen tool should not be tied to a specific service mesh. This will allow us to experiment with multiple service meshes in the future.
- GUI: Would be valuable to have, but at least some kind of deployment tracing related to what is happening under the hood in the alternative deployments would be necessary.
Affected/Related Systems
- Kubernetes deployment methods
- Application delivery strategies from Teams
Current Design
Native Kubernetes Deployment Objects:
- Rolling Update: A Rolling Update slowly replaces the old version with the new version. This is the default strategy of the Deployment object
- Recreate: Deletes the old version of the application before bringing up the new version. This ensures that two versions of the application never run at the same time, but there is downtime during the deployment.
Proposed Design
The aspirational goal is to add extra deployment capabilities to the current Kubernetes cluster and, therefore, increase the agility and confidence of application teams by reducing the risk of outages when deploying new releases.
The main benefits would be:
- Safer Releases: Reduce the risk of introducing a new software version in production by gradually shifting traffic to the new version while measuring metrics like request success rate and latency.
- Flexible Traffic Routing: Shift and route traffic between app versions with the possibility of using a service mesh (Linkerd, Istio, Kuma...) or not (Contour, NGINX, Traefik...)
- Extensible Validation: Extend the application analysis with custom metrics and webhooks for acceptance tests, load tests or any other custom validation.
- Progressive Delivery: Alternatives deployment strategies:
- Canary (progressive traffic shifting)
- A/B Testing (HTTP headers and cookies traffic routing): Called experiments by Argo Rollouts, although Canaries could have specific headers too.
- Blue/Green (traffic switching and mirroring)
Concepts
Blue/Green
It has both the new and old version of the application deployed at the same time. During this time, only the old version of the application will receive production traffic. This allows the developers to run tests against the new version before switching the live traffic to the new version.
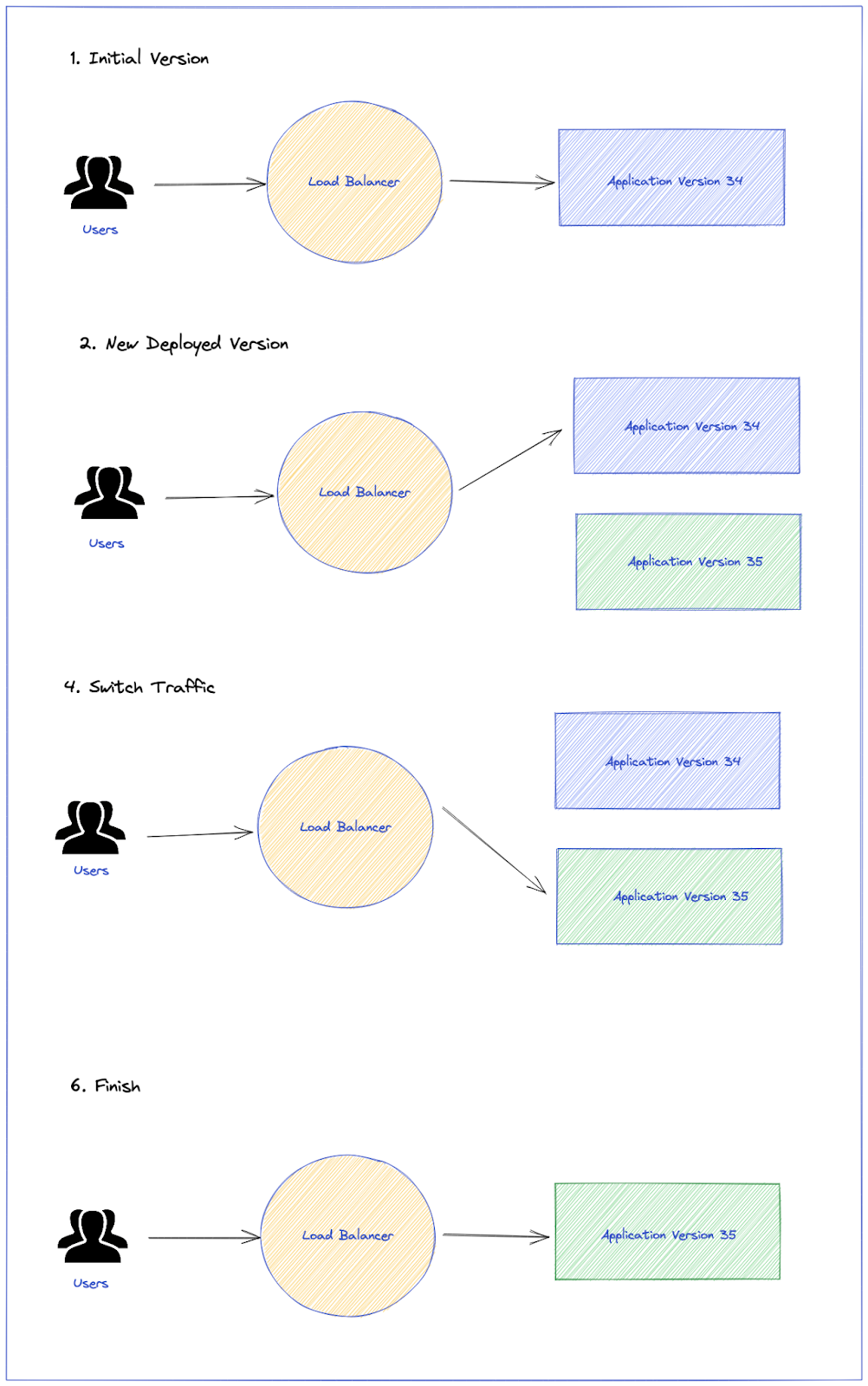
Canary
A Canary deployment exposes a subset of users to the new version of the application while serving the rest of the traffic to the old version. Once the new version is verified as being correct, it can gradually replace the old version. Ingress controllers and service meshes, such as NGINX and Istio, enable more sophisticated traffic shaping patterns for canarying than what is natively available (e.g. achieving very fine-grained traffic splitting, or splitting based on HTTP headers).
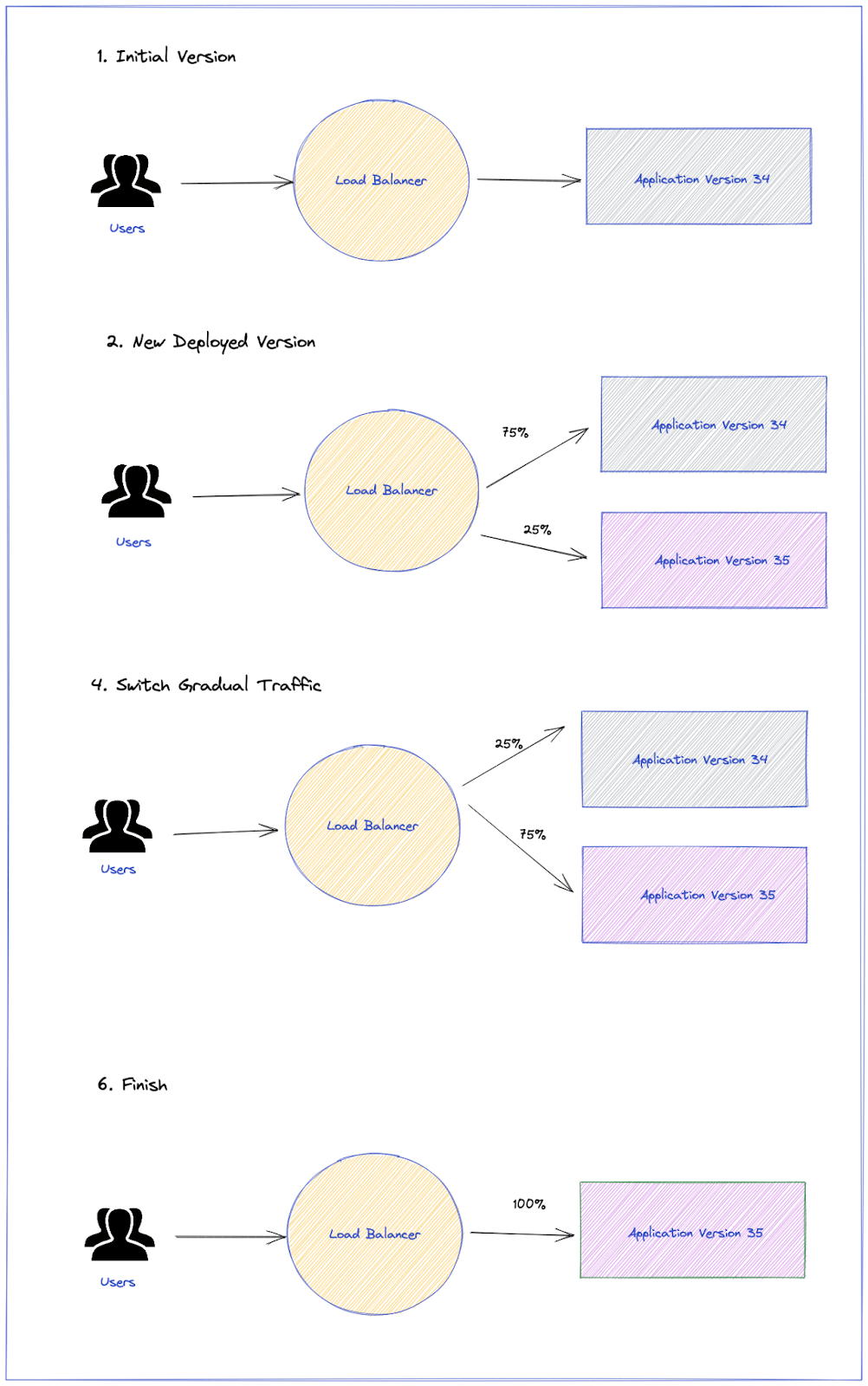
The picture above shows a Canary with two stages (25% and 75% of traffic goes to the new version), but this is just an example. Argo Rollouts allow multiple stages and percentages of traffic to be defined for each use case.
Tools
The two great projects are Argo Rollouts and Flagger. Both projects are mature and widely used.
Argo Rollouts
Argo Rollouts is a Kubernetes Controller and set of CRDs which provide advanced deployment capabilities such as Blue/Green, Canary, Canary analysis, experimentation and progressive delivery features to Kubernetes. A UI is deployed to see the different Rollouts.
Two kinds of rollouts:
Argo Rollouts offers experiments that allow users to have ephemeral runs of one or more ReplicaSets and run AnalysisRuns along those ReplicaSets to confirm everything is running as expected. Some use cases of experiments could be:
- Deploying two versions of an application for a specific duration to enable the analysis of the application.
- Using experiments to enable A/B/C testing by launching multiple experiments with a different version of their application for a long duration.
- Launching a new version of an existing application with different labels to avoid receiving traffic from a Kubernetes service. The user can run tests against the new version before continuing the Rollout.
A/B Testing could be performed using Argo Rollouts experiments
There are several ways to perform analysis to drive progressive delivery.
- AnalysisRuns are like Jobs, in that they eventually complete; the result of the run affects if the Rollout's update will continue, abort or pause. AnalysisRuns accept templating, making it easy to parametrize analysis.
- AnalysisRuns accepts multiple data sources like:
- Prometheus, querying over the applications metrics to foresee if the service has a degraded performance during the deployment
- Cloudwatch, querying over AWS metrics to check if everything is fine during the deployment
- Web, perform an HTTP request and compare against the result of a JSON response
- Job, execute a custom script in order to success/fail
Traffic Management
Observability
Migration
- Instead of modifying and creating a new rollout from scratch, Argo Rollouts allows reference Deployment from Rollout. This will reduce effort in the event of migration.
Pain Points:
- RBAC & Authentication
- Non-native integration: Argo Rollouts use their own CRD Rollout, not Kubernetes native
Flagger
Flagger is part of the Flux family of GitOps tools. Flagger is pretty similar to Argo Rollouts and its main highlights are:
- Native integration: It watches Deployment resources, not need to handle it using a CRD
- Highly extensible and comes with batteries included: It provides a load-tester to run basic or complex-scenarios
When you create a deployment, Flagger generates duplicate resources of your app (including configmaps and secrets). It creates Kubernetes objects with <targetRef.name>-primary and a service endpoint to the primary deployment.
It employs the same concepts about Canary, Blue/Green and A/B Testing as Argo Rollouts does.
Observability
Pain Points:
- No UI, so no RBAC and authentication are needed, but it's complex to have fast feedback from the current status of the rollouts. Checking the logs or checking the status of Canary resources is the only way.
- No kubectl plugin to check how the deployment is going; necessary to deal with
`kubectl logs -f flagger-controller`to see how kubectl describes Canary in order to check the progress. - Documentation could be better.
- Blue/Green is an adapted Canary (same as a Canary but with 100% weight)
Questions
What happens if the controller is down?
Argo Rollouts
- If there are Rollouts changes while the Argo Rollouts Controller is down, the controller will receive the latest changes; it's not going to start from where the Rollout was.
- If there is no new commit while the Controller is down, the Controller reconciles the status automatically. If the Rollout is in step 3 and the Controller is down, when it is back up, it will pick up from the same spot.
Flagger
- Like Argo Rollouts, it reconciles fine enough.
- The difference is that it follows the steps, instead of the previous changes and then the latest changes.
- New rollouts/deployments will be blocked, but the pods and HPA will remain up and running, even if it breaks in the middle of a rollout/deployment. Both Controllers will reconcile automatically after recovery.
What happens with the dashboards? Any changes?
Argo Rollouts
- Although we don't have a Deployment resource, metrics from deployments won't disappear.
Flagger
- Deployment resource is there, so no changes are expected.

- No changes
What happens when a Canary is paused on the GUI or command line? Is the GitOps setup going to override the change?
Argo Rollouts
- It can be done from the GUI and from the kubectl command line easily; the RolloutAbort will be notified by ArgoCD.
- It can be retried from the GUI easily or from kubectl commands; ArgoCD will mark the Rollout in progress
Flagger
- It looks like it's not possible to pause the deployment using the command line. It's needed to have Flagger Tester API deployed
What happens when a rollback occurs? What happens with the GitOps setup?
- Argo Rollouts is integrated with ArgoCD and the progress of the Rollout can be seen from ArgoCD UI.
- Flagger is not integrated with ArgoCD as seamlessly as Argo Rollouts, so a bunch of resources have been created and are visible in the ArgoCD UI, but there is no feedback.
What happens in lower environments with a Canary deployment if there is not enough traffic?
Argo Rollouts
- Argo Rollouts doesn't have a current way to do a loadtest directly but, as, a workaround it can be used with the webhooks to launch a k6 loadtest, as seen in this issue in their project.
- The loadtest has to be controlled out of the box; it specifically stops the loadtest when Canary reaches the step required.
Flagger
- It has integration with k6 loadtests through a webhook and offers a flagger-loadtest tool; more information on webhooks can be found here.
How does Canary traffic management work without a service mesh?
- In the absence of a traffic routing provider, both options can handle the Canary weights using NGINX capabilities. Besides, both options handle SMI and offer a broad selection related to service meshes. Then, whichever tool fits best and is not a blocker can be used to select one service mesh or another.
What happens when a configMap or secret used by the Deployment (as volume mounts, environment variables) are changed?
Argo Rollouts
- There is no support for that in Argo Rollouts, but there is an open issue in their Project
- Some workaround should be done, to be able to have rollout and rollback available when only a configMap changes. The workaround consists:
- Random suffix in the configMap name
- ConfigMap and Deployment definition in the same .yaml to avoid creating multiple random suffixes
Flagger
- Using the Helm annotation trick for automatically rolling out deployments when the configMap changes works well enough in the event of a rollout. But, for a rollback after the rollout, the same issue as the Deployments and ConfigMaps may appear because there is only one configMap, not multiple. That means the workaround for the rollback would have to be done in the same way as Argo Rollouts
To Sum Up
Both tools will help us to get alternative deployments, while there are some tradeoffs related to each tool:
Argo Rollouts
Pros
- Great UI, fast feedback
- Great integration and feedback with ArgoCD, indicating if the Rollout is in progress
- Easy integration with current Deployment resources
- Documentation
Cons
- UI without RBAC or auth
- Loadtest not integrated, it has to be added ad-hoc using a webhook
- Non-Kubernetes native, Rollout resource added by the CRD
Flagger
Pros
- Kubernetes native, doesn't introduce new Kubernetes resources
- Loadtest integrated
Cons
- No UI; feedback needs to be gathered through the K8s API
- Zero feedback from ArgoCD; Flagger integrates better with Flux, based on their documentation
- Documentation could be better
- Main differences with Argo Rollouts
- Feedback using kubectl commands
- Blue/Green is an adapted Canary (same as a Canary but with 100% weight, after some tests)
At Empathy, the tool we have chosen is Argo Rollouts. It fits our needs pretty well, offers faster feedback, has great integration with ArgoCD, and is open to more complex strategies.
What's next?
- Choose your fighter, adapt the strategies to your applications. Likely some apps fit better with a Blue/Green approach and others with a Canary approach.
- Demo Session in lower environments.
- Plan migration with Teams.
- Capabilities could be improved in the future if/when a Service Mesh is added to the Platform.
References
- https://argoproj.github.io/argo-rollouts/
- https://docs.flagger.app/
- https://thenewstack.io/more-problems-with-gitops-and-how-to-fix-them/
- https://devopsian.net/posts/kubernetes-canary-deployments/
- https://docs.flagger.app/usage/webhooks#load-testing
- https://argoproj.github.io/argo-rollouts/migrating/#reference-deployment-from-rollout
