Running Apache Flink on Kubernetes
Categories
During the last weeks, I was deploying a Flink cluster on Kubernetes cluster. I’d like to share the challenges, architecture, Kubernetes deployment, solution details and the journey on this article
Challenges
At Empathy, all code running in Production must be cloud agnostic. Empathy had a cloud dependency regarding Dataflow (in the GCP scenario) and Kinesis Data Analytics (in the AWS scenario).
The data streaming job code is developed in Apache Beam; therefore, it could run over Apache Flink. The default way to deploy a job in Apache Flink is to upload a JAR containing the job and its dependencies to a running Flink cluster. This solution can’t be a mid-term solution for such reasons as traceability for JAR files, how to distribute these JAR files, how Continuous Deployment should be done, and localhost execution, to mention a few reasons.
- Encapsulating everything as a Docker image allows Empathy to achieve better traceability of the Apache Flink jobs, to distribute the Apache Flink jobs as other normal Docker images, and use the same continuous deployment model as the rest of the applications.
- Besides, Kubernetes has been adopted for a bunch of applications as the orchestration solution at Empathy. So Data Streaming Stack should be just one more app in this orchestration solution, enjoying the same benefits as the rest of the apps living on a K8s cluster and remaining portable from localhost to production.
Then, running Apache Flink on Kubernetes (K8s) would offer us the following fundamentals:
- Scalability: The new solution should be able to scale according to its needs
- Reliability: The new solution should monitor compute nodes and automatically terminate and replace instances in case of failure
- Portability: The new solution should be able to be deployed in whatever cloud solution, avoiding the cloud provider dependency
- Cost-effectiveness: The new solution should reduce the cost of managed services
- Monitoring: The new solution should include ad-hoc monitoring
Apache Flink Architecture
Feel free to skip this section if you are already familiar with Apache Flink.
Apache Flink has two main components:
- Job Manager. Its mission is to distribute work onto multiple TaskManagers
- Task Manager. Its mission is to perform the work of a Flink job.
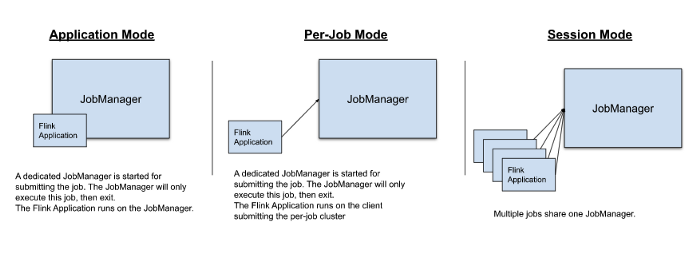
Flink can execute application in one of these three ways:

The main differences between these three ways are:
- Cluster lifecycle and resource isolation
- Whether the application’s main() method is executed on the client or on the cluster
Empathy Data Streaming required an Application Mode. A new Apache Flink cluster would be deployed for each Data Streaming job. Therefore, this would provide better isolation for the applications.
Another interesting topic would be how to be resilient using Apache Flink. This is where checkpoints and savepoints would appear. The current implementations of Checkpoints and Savepoints are pretty much the same. Their main differences are:
Checkpoints
- Their use case is for self healing in case of unexpected job failures
- They are created, owned and released by Flink (without user interaction)
- Don’t survive job termination (except retained Checkpoints)
Savepoints
- Pretty similar to checkpoints but with extra data info
- Their use case is for updates in Flink version, parallelism changes, maintenance windows and so on
- They are created, owned and released by user
- Survive job termination
Empathy Data Streaming required use checkpoints and savepoints to be fault tolerant as well as self healing in case of some unexpected job failures. Therefore, JobManager High Availability(HA) is needed, also, because JobManager HA ensures that a Flink cluster always continues executing the submitted jobs.

Apache Flink Kubernetes Deployment
The reasons to deploy Apache Flink over Kubernetes were mentioned in the challenges section. To sum up:
- Job image distribution
- Continuous Deployment as with the rest of Empathy’s apps
- Portability: From localhost to production
To deploy Apache Flink 1.12 on Kubernetes, there are two main candidate approaches:
- Standalone mode
- Kubernetes Native
Standalone mode
Standalone mode is the most barebones way of deploying Flink. The basic cluster will have:
- a Deployment for the JobManager
- a Deployment for the TaskManagers
- a Service exposing the JobManager API REST, UI ports
- an Ingress to access UI service port
- a Service exposing the JobManager and TaskManagers metrics
- a ServiceMonitor sending the metrics from the service to Prometheus
- some ConfigMaps to pass configurations settings such as flink-conf.yaml, logback-console.xml, log4j-cli.properties or log4j-console.properties if required
The main pain point of this setup is that it requires a huge knowledge of Kubernetes to define every Kubernetes resource and apply the glue between the different resources.

This method provides monitoring, self healing and HA.
Kubernetes Native
Flink Kubernetes Native directly deploys Flink on a running Kubernetes cluster. Using this approach, only a command is needed to deploy an Apache Flink cluster in Application Mode with the needed resources and correct setup.
To use Kubernetes Native, one must include the JAR file in the Docker build image. To start the cluster, just a simple command is needed:
flink run-application \
--fromSavepoint=${FROM_SAVEPOINT} \
-Dkubernetes.container.image=${REPOSITORY_PATH}:${IMAGE_TAG} \
-Dparallelism.default=${PARALLELISM} \
--target kubernetes-application \
local:///opt/flink/usrlib/job.jar
The command above could be launched from localhost or from the Kubernetes cluster, and it would create the JobManager and TaskManagers pods that are requested by the command. Besides, the config could be passed using configmaps to avoid inline settings. You can explore all the configuration possibilities in the official doc.
The following resources are needed:
- a Job to orchestrate the cluster creation and take a savepoint before starting a new Flink cluster
- a Service exposing the JobManager API REST, UI ports
- an Ingress to access UI service port
- a PodMonitor sending the metrics from each jobManager and TaskManager pod to Prometheus
- some ConfigMaps to pass configurations settings such as flink-conf.yaml, logback-console.xml, log4j-cli.properties or log4j-console.properties if required

The decision at Empathy to use Apache Flink Kubernetes Native in Application Mode was mainly because using this method, the jobManager and TaskManager resources (requests/limits) are automatically handled by Flink Native. Hence, it will aid in an easy configuration setup while maintaining all the benefits of the other solution such as monitoring, self healing and HA.
Solution Details
Monitoring
Providing metrics from JobManagers and TaskManagers are crucial in Data Streaming jobs. Prometheus metrics can be exposed by Apache Flink by setting the needed config.
The metrics are exposed through port 9249 in each jobManager and TaskManager pod. The logic would be to group these metrics in a service and create a serviceMonitor to send metrics to Prometheus. Nevertheless, using Apache Flink Kubernetes Native 1.12 can’t specify pod templates to use a ServiceMonitor. Therefore, the solution is to create a podMonitor to send the metrics of each jobManager, TaskManager port to Prometheus. Here’s a podMonitor sample:
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
labels:
release: prometheus
name: k8s-ha-flink
namespace: flink
spec:
podMetricsEndpoints:
- path: /
relabelings:
- action: replace
replacement: '$1:9249'
sourceLabels:
- __meta_kubernetes_pod_ip
targetLabel: __address__
selector:
matchLabels:
app: k8s-ha-flink
Once Prometheus scrapes the metrics, some Grafana Dashboards are needed. The custom Grafana Dashboards for Apache Flink are based on the following dashboards from the community:
State and Fault Tolerance
Checkpoints make state in Flink fault tolerant by allowing state and the corresponding stream positions to be recovered, thereby giving the application the same semantics as a failure-free execution.
Savepoints, pretty similar to checkpoints, allow rescaling the cluster or a version upgrade.
The checkpoints and savepoints will be enabled and persisted on buckets.
Self Healing and HA
Empathy Data Streaming jobs usually handle a huge load of requests, and the application should offer a near real-time response. Therefore, it’s important that the cluster heal from failures without manual intervention and recover from the latest checkpoint. Besides, it would be nice for multiple jobManagers to have High Availability.
Native Kubernetes HA for Apache Flink resolves this concern. Therefore, the Native Kubernetes HA will be enabled and set in all Empathy Apache Flink clusters.
Based on the experience of two months running this setup, Kubernetes Native HA for Flink doesn’t support multiple jobManagers at the same time. A solution is anticipated in the next big release, 1.13. Until then, Empathy considers the self healing mechanism sufficient for production load.
Job Update
In case a new Apache Flink cluster deployment is needed, take a savepoint before terminating the cluster. Since for each streaming job there is a dedicated cluster, some time must be dedicated to test and analyze how to do the update.
The approach is to include a custom stop step in the orchestration Job:
- The Job starts and it will launch the stop command for a specific Flink cluster passed by environment variables in the job definition
If the Flink cluster exists
- Take a savepoint using the Flink REST API
- Wait until the savepoint has been completed or exit after timeout
- Once completed, save the savepoint in a bucket and create/update a configmap with the new bucket path for the savepoint saved
- Delete the Flink cluster. For Kubernetes Native, this means deleting the deployment with the Flink cluster. Note that the configMaps related to selfHealing and HA will be deleted too
If the cluster does not exist, don’t take a savepoint
Once the stop step has been done, the start cluster can be executed:
- Apache Flink will mount the configMap where the bucket path for the savepoint was saved
If there is a bucket path in the configmap
- Apache Flink will start from the savepoint
If the bucket path is null in the configmap
- Apache Flink will start from scratch
Therefore, this method is guaranteed to start from a savepoint in case a new job is needed to deploy. Some use cases might be:
- Update a Flink version
- Change the job graph
- Change parallelism
- Fork a second job
Future
Apache Flink community usually takes a new release each six months. Some interesting issues will be solved in Apache Flink 1.13:
- Reactive Mode or Autoscaling. This may allow task managers to scale automatically based on the load. It would be nice to save cost and resources. More info here.
- Support user-specified pod templates. This will be useful to set specific ports, init containers, and labelling. More info here.
- Implement File System HA Service for Native Kubernetes. To avoid a Zookeeper installation and use jobManager HA. More info here.
This has been a long article and we’ve learned a lot the way. I hope our learnings will help you to become more cloud agnostic.
If you would like to help us improve our Platform, please consider joining our Teams at Empathy.co
